(ESAM)Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance 论文笔记
本文主要想要解决的问题是,在 召回层 中,由于 sample selection bias 导致的曝光样本与未曝光样本之间的 domain shift 问题
Sample selection bias
定义为:用于分析的数据使用了不能保证随机化得方法获得,因此从样本中分析的结果不能代表总体特征;
比如:
- 在大学中开展社会调查,实际上是condition on受访者上过大学
- 使用某个在线网站上的数据做分析,实际上是condition on用户会访问该网站
- 分析从战场返回的战斗机上的弹孔位置,实际上是condition on飞机没有被击落
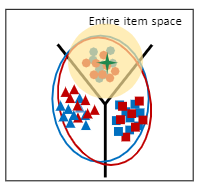
用论文中的一张图来进行说明:
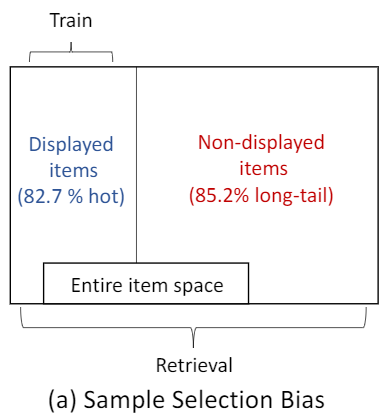
可以看出曝光的商品中82.7%是hot的,也就是说82.7%的商品是经常出现在各个用户的曝光商品中的;而未曝光的商品中有85.2%的商品是长尾的,即几乎始终处于各个用户的未曝光列表中的。这样会导致我们的召回模型能够很好的学到已曝光商品的向量表征,但是无法学到未曝光商品的向量表征。目前采取的做法有:
- (正向)纠正曝光样本与未曝光样本之间的 domain shift 问题
- (反向)在训练模型时,增强负采样对于负样本的选择,增强模型的学习难度,保证了模型对于负样本的向量表征,一般使用的是 hard negative
召回策略
目前的召回策略均是基于embedding的,整体流程如下: \[ \begin{array}{l} \boldsymbol{v}_{q}=f_{q}(q),\quad \boldsymbol{v}_{d}=f_{d}(d) \end{array} \]
\[ S c_{q, d}=f_{s}\left(v_{q}, v_{d}\right) \]
根据 domain shift,我们将问题归结为 \(f_{d}\) 在处理未曝光样本时的问题
Domain shift
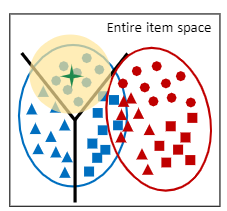
即曝光商品的向量表征空间与未曝光商品的向量表征空间不统一
本文的解决方法
我们称曝光的item组成的域为source domain,未曝光的item组成的域为target domain
整体的解决方法一共分为三步:
Domain Adaptation with Attribute Correlation Alignment:通过一种 间接 的特征对齐,将曝光商品与未曝光商品的向量表征空间统一起来,这时候source domain与target domain会发生重叠,即:
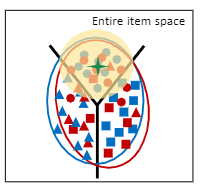
此时我们会发现,由于target domain中的item没有标签,此时虽然domain发生了重叠,但是很多红色的target item都分类错误了;接下来我们的任务就主要集中在对target item进行正确的分类;一共分类两步!
Center-Wise Clustering for Source Clustering:通过第一步,我们可以使得target domain的分布屈从于source domain的分布,这一步我们使得source domain中的同一标签的item之间更加内聚,距离分类边界更远,即“高内聚,低耦合”,这样target也会屈从于这样的趋势。此时分布图会变成如下:
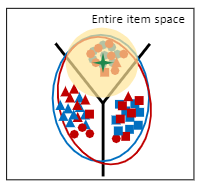
Self-Training for Target Clustering:我们通过上图可以看出,虽然相互间的分界线很明显,但是target item还是会存在分类错误的情况!原因依旧是因为大部分的target domain的商品没有标签!这一步我们会为每一个item打上 伪标签,通过伪标签对模型进行训练。经过最后一步,总体分布会变成下图:
具体算法
注意:我们模型可以看做是一个 插件 ,是对原本召回模型中的未曝光商品训练的加强
Domain Adaptation with Attribute Correlation Alignment
我们首先寻找特征与特征之间的相互关系,制造特征间的协方差矩阵。
举个低维特征间相似性的例子,一个商品牌子越大,价格就越高;而一个商品的牌子和材料之间的关联程度就较弱,因此我们可以得到下图(a):
我们认为可以将这一地位特征间的相关性推导到高维特征,得到图(b)
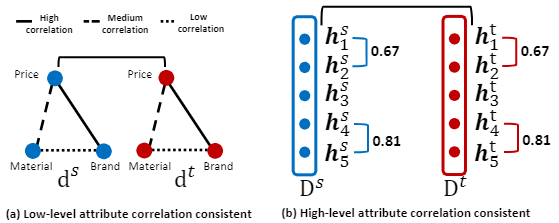
然后通过拟合source domain的协方差矩阵和target domain之间的协方差矩阵,实现source domain和target domain之间特征空间的 伪对齐。具体做法为:
假设对于每个query "q"
- 我们收集了n个“曝光item”(来自source domain)和用户对它们的反馈。这n个item经过\(f_{d}\)映射,映射成\(D^{s} \in R^{n * L}\),L是embedding的维度
- 我们再随机抽样n个“未曝光item”(来自target domain),它们经过\(f_{d}\)映射,映射成\(D^{s} \in R^{n * L}\)
- 我们要求:的L维高阶特征的两两之间(\(h_{j^{\prime}}^{s}\)和\(h_{k}^{s}\))的协方差,与的L维高阶特征的两两之间(\(h_{j^{\prime}}^{t}\)和\(h_{k}^{t}\))的协方差,两者之间的差值尽可能小
\[ \begin{aligned} L_{D A} &=\frac{1}{L^{2}} \sum_{(j, k)}\left(\boldsymbol{h}_{j}^{s \top} \boldsymbol{h}_{k}^{s}-\boldsymbol{h}_{j}^{t \top} \boldsymbol{h}_{k}^{t}\right)^{2} \\ &=\frac{1}{L^{2}}\left\|\operatorname{Cov}\left(D^{s}\right)-\operatorname{Cov}\left(D^{t}\right)\right\|_{F}^{2} \end{aligned} \]
Center-Wise Clustering for Source Clustering
为了实现source domain内的“高耦合,低内聚”,我们加入如下Loss: \[ \begin{aligned} L_{D C}^{c} &=\sum_{j=1}^{n} \max \left(0,\left\|\frac{\boldsymbol{v}_{d_{j}^{s}}}{\left\|\boldsymbol{v}_{d_{j}^{s}}\right\|}-\mathbf{c}_{q}^{y_{j}^{s}}\right\|_{2}^{2}-m_{1}\right) +\sum_{k=1}^{n_{y}} \sum_{u=k+1}^{n_{y}} \max \left(0, m_{2}-\left\|\mathbf{c}_{q}^{k}-\mathbf{c}_{q}^{u}\right\|_{2}^{2}\right) \end{aligned} \] 其中: \[ \mathrm{c}_{q}^{k}=\frac{\sum_{j=1}^{n}\left(\delta\left(y_{j}^{s}=Y_{k}\right) \cdot \frac{v_{d}^{s}}{\left\|\boldsymbol{v}_{j_{j}^{s}}\right\|}\right)}{\sum_{j=1}^{n} \delta\left(y_{j}^{s}=Y_{k}\right)} \] 第一个公式的理解如下:
- 公式中的第1项是为了达到“同一类feedback中的item embedding”要“高内聚”的目标,其中 \(c_{q}^{y_{j}^{s}}\) 代表属于某个feedback的所有item embedding的平均,作为这一类feedback的item embedding的中心
- 公式中的第2项是为了达到“不同类feedback的item embedding”要“低耦合”的目标,表现在不同feedback的item embedding的中心要尽可能远
Self-Training for Target Clustering
添加伪标签的具体做法如下:
- 训练中,如果根据当前模型,query "q"已经与某“未曝光item”的匹配得分相当低了(小于阈值p1),我们就认为这对<>是负样本,接下来的训练中,\(<q, d^{t}>\)得分要变得越来越小,趋近0
- 训练中,如果根据当前模型,query "q"已经与某“未曝光item”的匹配得分相当高了(大于阈值p2),我们就认为这对<>是正样本,接下来的训练中,\(<q, d^{t}>\)得分要变得越来越大,趋近1
具体实现时,ESAM并不需要动态修改label。因为修改label的目的,仅仅是为了接下来的优化指明方向,所以ESAM使用如下辅助task达到同样的效果: \[ L_{D C}^{p}=-\frac{\sum_{j=1}^{n} \delta\left(S c_{q, d_{j}^{t}}<p_{1} \mid S c_{q, d_{j}^{t}}>p_{2}\right) S c_{q, d_{j}^{t}} \log S c_{q, d_{j}^{t}}}{\sum_{j=1}^{n} \delta\left(S c_{q, d_{j}^{t}}<p_{1} \mid S c_{q, j}^{t}>p_{2}\right)} \] 其中\(\delta\)是condition function,表示这种"伪label"只在预估的匹配得分太高或太低,即模型有充分自信时,才添加,之所要设置p1,p2这两个阈值,是因为:模型一开始无法得到很好的训练,对于target item的打分存在一定的容错,因此我们需要保护 [p1, p2] 中间这一段不做分类!
Final
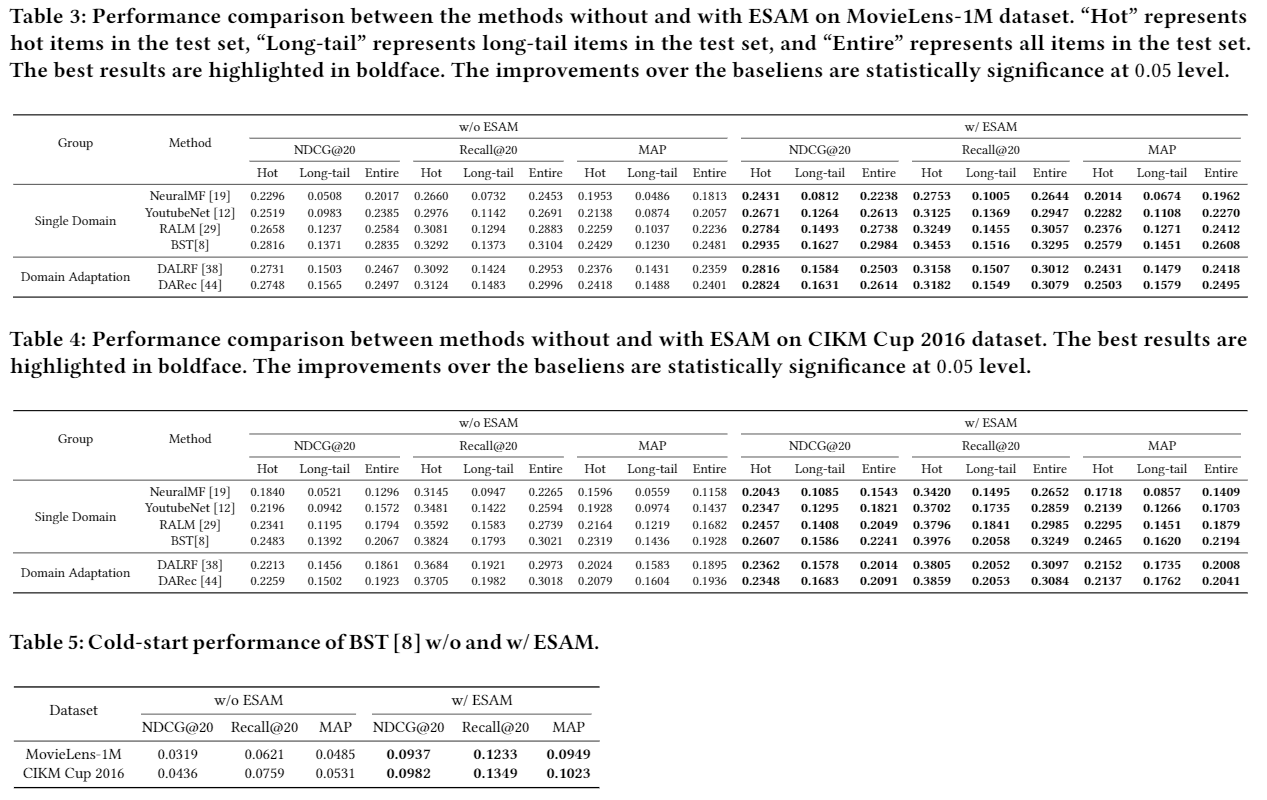
总的Loss最终设置如下: \[ L_{a l l}=L_{s}+\lambda_{1} L_{D A}+\lambda_{2} L_{D C}^{c}+\lambda_{3} L_{D C}^{p} \] 梯度下降的方式如下: \[ \Theta^{t+1}=\Theta^{t}-\eta \frac{\partial\left(L_{s}+\lambda_{1} L_{D A}+\lambda_{2} L_{D C}^{c}+\lambda_{3} L_{D C}^{p}\right)}{\partial \Theta} \] 最终提升效果如下:
Reference
[1] ESAM: Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance
(ESAM)Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance 论文笔记