(KGAT)Knowledge Graph Attention Network for Recommendation 论文笔记
创新点
CF(collaborative filtering)方法强调的是:交互过相同的item的user会继续交互相同的item。
SL(supervised learning)方法强调的是:通过KG构建item之间的联系,建立high-order relation,挖掘user之间的隐藏关系。如下图所示,u1和黄色圈、灰色圈的联系只能通过SL的方法来发掘
构建CKG网络
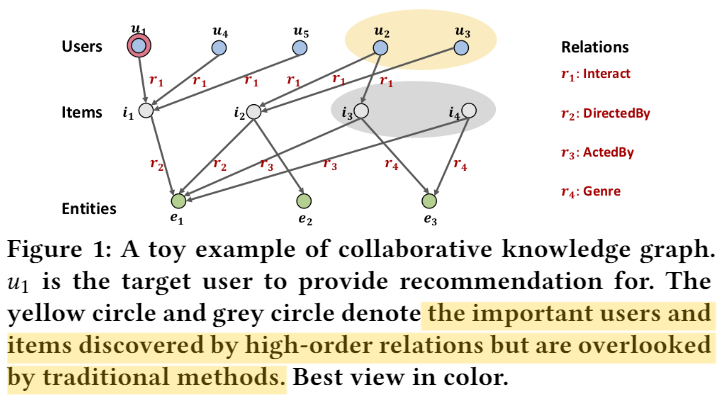
因此我们构建的网络为collaborative knowledge graph (CKG),即Figure 1所示的那样。
图神经网络中加入attention
对于不同的点在图中进行传播是,使用不同的attention
模型
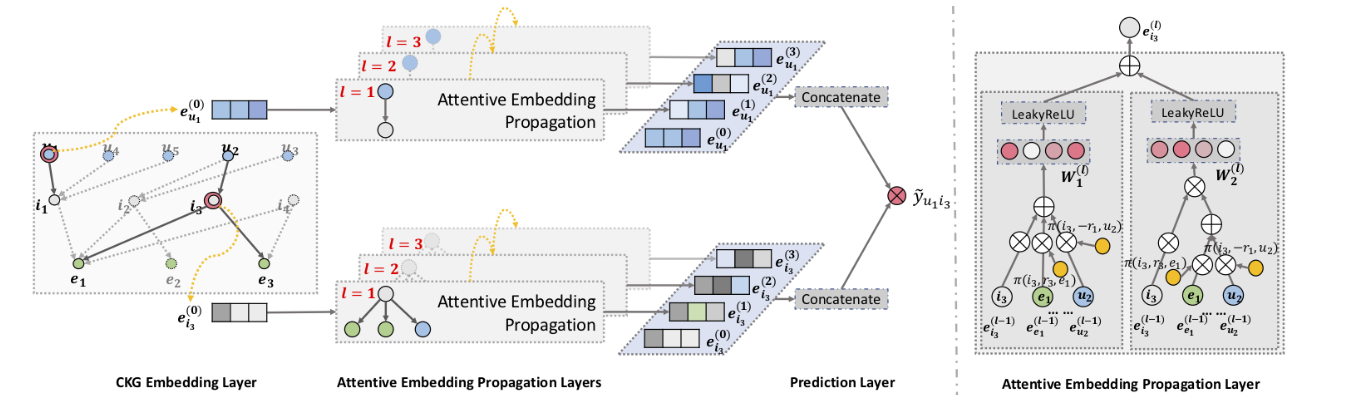
Embedding Layer
为了建模CKG之间的关系,使用了TransR的方法,即:
三元组之间可信度的计算方式为: \[ g(h, r, t)=\left\|\mathrm{W}_{r} \mathbf{e}_{h}+\mathrm{e}_{r}-\mathrm{W}_{r} \mathrm{e}_{t}\right\|_{2}^{2} \] 同时引入KG的loss为: \[ \mathcal{L}_{\mathrm{KG}}=\sum_{\left(h, r, t, t^{\prime}\right) \in \mathcal{T}}-\ln \sigma\left(g\left(h, r, t^{\prime}\right)-g(h, r, t)\right) \] 其中: \[ \mathcal{T}=\left\{\left(h, r, t, t^{\prime}\right) \mid(h, r, t) \in G,\left(h, r, t^{\prime}\right) \notin G\right\} \]
Attentive Embedding Propagation Layers
分别对于CKG中的user和item节点学习各自的representation,具体的实现方法如下:
Information Propagation \[ \mathbf{e}_{\mathcal{N}_{h}}=\sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathbf{e}_{t} \]
Knowledge-aware Attention \[ \pi(h, r, t)=\left(\mathbf{W}_{r} \mathbf{e}_{t}\right)^{\top} \tanh \left(\left(\mathbf{W}_{r} \mathbf{e}_{h}+\mathbf{e}_{r}\right)\right) \]
\[ \pi(h, r, t)=\frac{\exp (\pi(h, r, t))}{\sum_{\left(h, r^{\prime}, t^{\prime}\right) \in \mathcal{N}_{h}} \exp \left(\pi\left(h, r^{\prime}, t^{\prime}\right)\right)} \]
Information Aggregation
GCN Aggregator: \[ f_{\mathrm{GCN}}=\text { LeakyReLU }\left(\mathrm{W}\left(\mathrm{e}_{h}+\mathrm{e}_{\mathcal{N}_{h}}\right)\right) \]
GraphSage Aggregator: \[ f_{\text {GraphSage }}=\text { LeakyReLU }\left(\mathbf{W}\left(\mathbf{e}_{h} \| \mathbf{e}_{\mathcal{N}_{h}}\right)\right) \]
Bi-Interaction Aggregator: \[ \begin{aligned} f_{\text {Bi-Interaction }}=& \text { LeakyReLU }\left(\mathbf{W}_{1}\left(\mathbf{e}_{h}+\mathbf{e}_{\mathcal{N}_{h}}\right)\right)+\\ & \text { LeakyReLU }\left(\mathbf{W}_{2}\left(\mathbf{e}_{h} \odot \mathbf{e}_{\mathcal{N}_{h}}\right)\right), \end{aligned} \]
High-order Propagation
将Attentive Embedding Propagation Layer堆叠起来实现递归式的传播 \[ \mathbf{e}_{h}^{(l)}=f\left(\mathbf{e}_{h}^{(l-1)}, \mathbf{e}_{\mathcal{N}_{h}}^{(l-1)}\right) \]
\[ \mathrm{e}_{\mathcal{N}_{h}}^{(l-1)}=\sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathrm{e}_{t}^{(l-1)} \]
Model Prediction
为了防止图神经网络的过平滑,将多层graph representation拼接起来: \[ \mathrm{e}_{u}^{*}=\mathrm{e}_{u}^{(0)}\|\cdots\| \mathrm{e}_{u}^{(L)}, \quad \mathrm{e}_{i}^{*}=\mathrm{e}_{i}^{(0)}\|\cdots\| \mathrm{e}_{i}^{(L)} \] 得分计算: \[ \hat{y}(u, i)=\mathbf{e}_{u}^{* \top} \mathbf{e}_{i}^{*} \]
Optimization
预测Loss:(BPR) \[ \mathcal{L}_{\mathrm{CF}}=\sum_{(u, i, j) \in O}-\ln \sigma(\hat{y}(u, i)-\hat{y}(u, j)) \] 模型总的Loss: \[ \mathcal{L}_{\mathrm{KGAT}}=\mathcal{L}_{\mathrm{KG}}+\mathcal{L}_{\mathrm{CF}}+\lambda\|\Theta\|_{2}^{2} \]
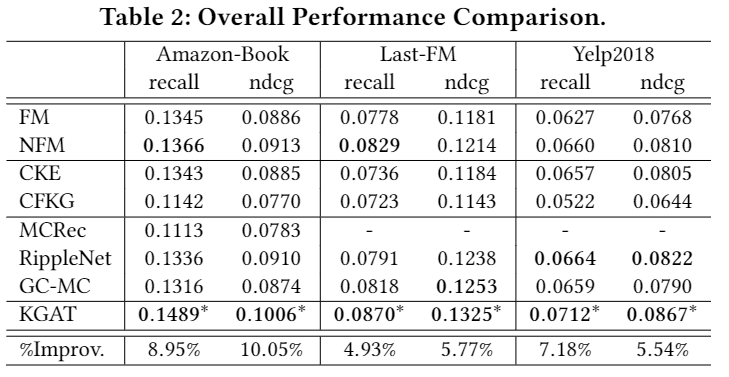
实验结果
(KGAT)Knowledge Graph Attention Network for Recommendation 论文笔记