(KRED)Knowledge-Aware Document Representation for News 论文笔记
Intro
正如文章的名字Knowledge-Aware Document Representation for News Recommendations,这篇文章更注重的是创建一个位于任务上游的news representation,为位于下游的新闻推荐子任务提供类似BERT在NLU领域的工具。
创新点
- 认为现存的文档理解模型要么是没有考虑知识图谱信息,比如BERT;要么是依赖于特殊的文章编码模型,以至于缺乏泛化能力和效率,比如DKN。本篇文章将知识图谱与BERT相结合
- 对于每一个实体在经过知识图谱表示层后,又加入了上下文信息,即context embedding层
模型
整体模型分为三层,分别是:
Entity Representation Layer:使用Knowledge Graph Attention (KGAT) Network,将知识图谱中当前实体周围实体的信息汇聚与当前实体,用于增强对于当前实体的表示。其具体公式如下:
\[ \mathbf{e}_{\mathcal{N}_{h}}=\operatorname{ReLU}\left(\mathbf{W}_{0}\left(\mathbf{e}_{h} \oplus \sum_{(h, r, t) \in \mathcal{N}_{h}} \pi(h, r, t) \mathbf{e}_{t}\right)\right) \]
其中Nh表示以h为头部实体的三元组,\(\pi(h, r, t)\)表示注意力权重,用来控制周围节点传播多少信息量到中心节点,其计算方式如下:
\[ \pi_{0}(h, r, t)=\mathbf{w}_{2} \operatorname{Re} L U\left(\mathbf{W}_{1}\left(\mathbf{e}_{h} \oplus \mathbf{e}_{r} \oplus \mathbf{e}_{t}\right)+\mathbf{b}_{1}\right)+b_{2} \]
\[ \pi(h, r, t)=\frac{\exp \left(\pi_{0}(h, r, t)\right)}{\sum_{\left(h, r^{\prime}, t^{\prime}\right) \in \mathcal{N}_{h}} \exp \left(\pi_{0}\left(h, r^{\prime}, t^{\prime}\right)\right)} \]
Context Embedding Layer:为每一个实体向量加入位置、频率、类别这三种信息,通过wise-to-wise的直接相加
Information Distillation Layer:使用类似self-attention的机制来得到news representation
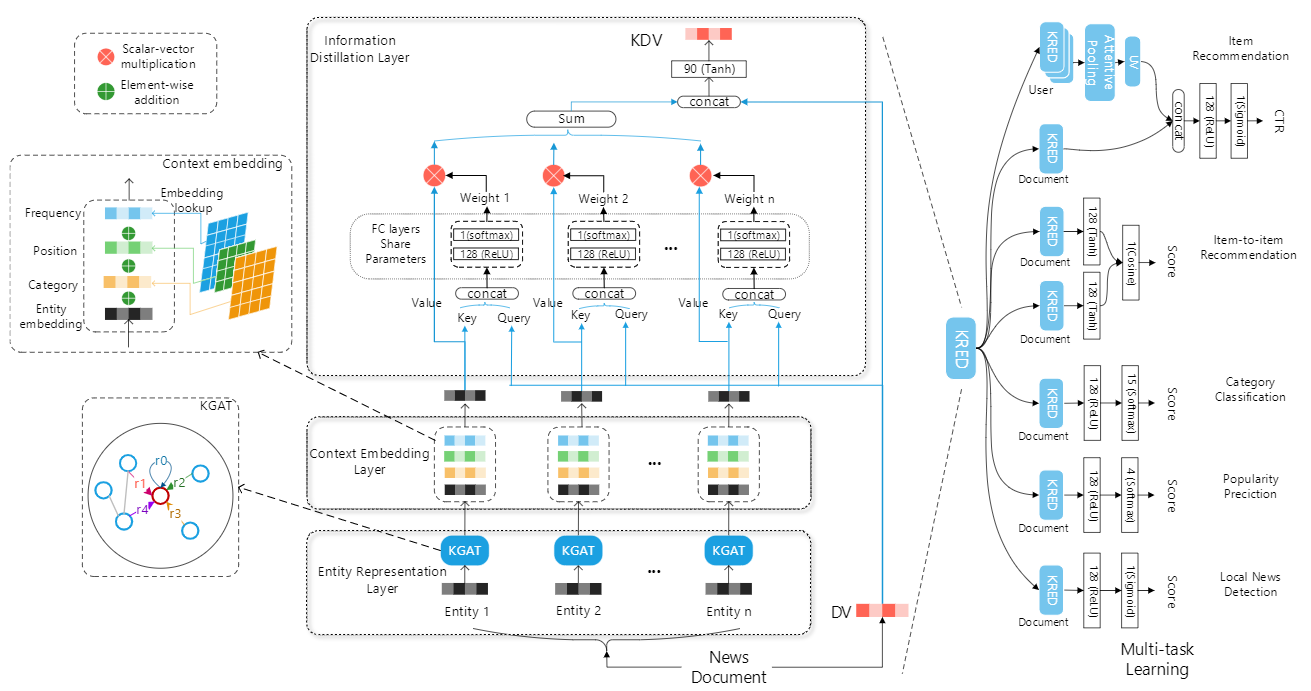
随后,为了提升这个上游模型的性能,对该模型进行Multi-Task的学习(包含Category Classification、Popularity Prediction、Local News Detection、Item Recommendation、Item-to-item Recommendation),一共分为两个阶段:
- stage1:we alternately train different tasks every few mini-batches.
- stage2:we only include the target task’s data to finalize a task-specific model.
反思
- 对于知识图谱的使用:其中对于知识图谱的使用也是在news representation的阶段,处于整体模型的第一层
(KRED)Knowledge-Aware Document Representation for News 论文笔记