(CKAN)Collaborative Knowledge-aware Attentive Network for Recommender Systems 论文笔记
CKAN: Collaborative Knowledge-aware Attentive Network for Recommender Systems
Intro
文章认为现有的基于KG的方法存在着一些问题,即:
只利用了知识图谱中entity之间的连接信息来丰富item的语义信息,没有利用collaborative signals
对此本文提出新的模型Collaborative Knowledge-aware Attentive Network (CKAN),用于将collaborative signals和knowledge associations结合起来
collaborative signals: which assumes that users with similar behaviors may have similar appetites for items,
创新点
- Heterogeneous propagation: composed of collaboration propagation and knowledge graph propagation, views interaction and knowledge as information in two different spaces and combines them in a natural way.
- Knowledge-aware attentive embedding: a brand new knowledge-aware neural attention mechanism proposed for learning different weights of neighbors in KG when they are in different conditions.
模型
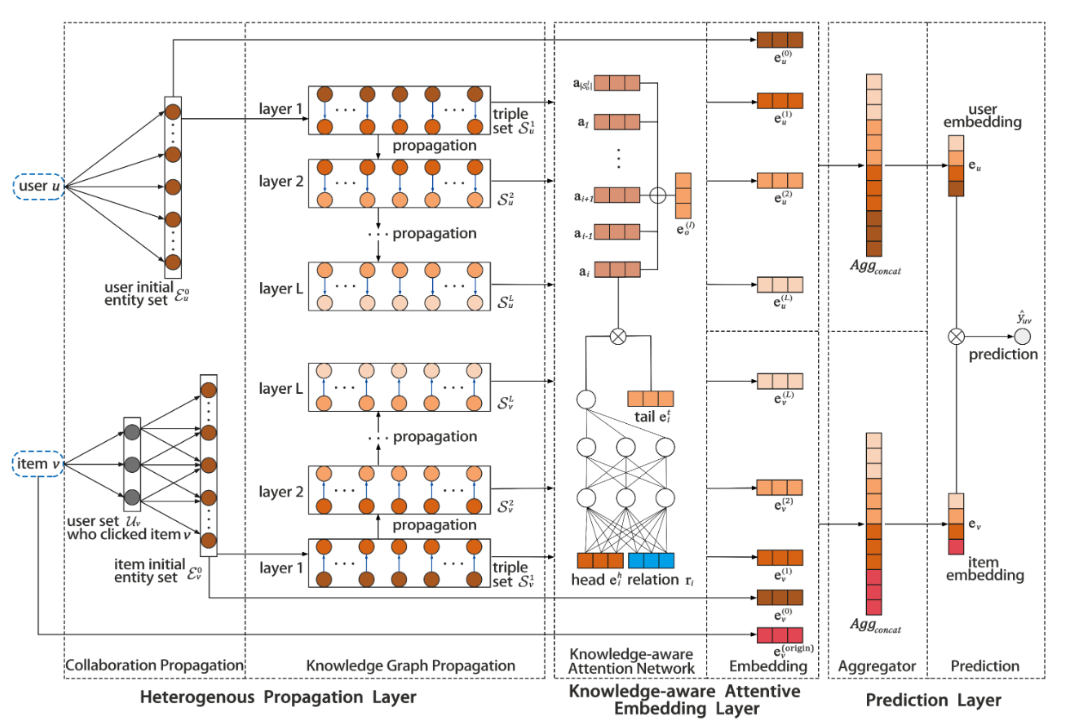
Heterogeneous Propagation Layer
用于融合知识图谱和协同信号
Collaboration Propagation
对于item的neighbor的确定:
\[ \mathcal{V}_{v}=\left\{v_{u} \mid u \in\left\{u \mid y_{u v}=1\right\} \text { and } y_{u v_{u}}=1\right\} \]
\[ \mathcal{E}_{v}^{0}=\left\{\mathrm{e} \mid\left(v_{u}, \mathrm{e}\right) \in \mathcal{A} \text { and } v_{u} \in \mathcal{V}_{v}\right\} \]
对于user的neighbor的确定: \[ \mathcal{E}_{u}^{0}=\left\{\mathrm{e} \mid(v, \mathrm{e}) \in \mathcal{A} \text { and } v \in\left\{v \mid y_{u v}=1\right\}\right\} \]
Knowledge Graph Propagation
对于上一阶段得到的seed set,在知识图谱中逐层传播,每一层得到的entity作为一个集合保存
\[ \mathcal{S}_{o}^{l}=\left\{(h, r, t) \mid(h, r, t) \in \mathcal{G} \text { and } h \in \mathcal{E}_{o}^{l-1}\right\}, \quad l=1,2, \ldots, L \]
Knowledge-aware Attentive Embedding Layer
对于每一个扩展出来的entity,使用attention进行计算,attention机制使用两层全连接网络实现:
\[ \begin{aligned} \mathrm{z}_{0} &=\operatorname{ReLU}\left(\mathrm{W}_{0}\left(\mathrm{e}_{i}^{h} \| \mathrm{r}_{i}\right)+\mathrm{b}_{0}\right) \\ \pi\left(\mathrm{e}_{i}^{h}, \mathrm{r}_{i}\right) &=\sigma\left(\mathrm{W}_{2} \operatorname{ReLU}\left(\mathrm{W}_{1} \mathrm{z}_{0}+\mathrm{b}_{1}\right)+\mathrm{b}_{2}\right) \end{aligned} \]
最后经过softmax得到如下:
\[ \pi\left(\mathrm{e}_{i}^{h}, \mathrm{r}_{i}\right)=\frac{\exp \left(\pi\left(\mathrm{e}_{i}^{h}, \mathrm{r}_{i}\right)\right)}{\sum_{\left(h^{\prime}, r^{\prime}, t^{\prime}\right) \in \mathcal{S}_{o}^{l}} \exp \left(\pi\left(\mathrm{e}_{i}^{h^{\prime}}, \mathrm{r}_{i}^{\prime}\right)\right)} \]
其中第0层的计算略有不同,因为第0层的贡献都很大,因此采用如下的方法:
\[ \mathrm{e}_{o}^{(0)}=\frac{\sum_{\mathrm{e} \in \mathcal{E}_{o}^{0}} \mathrm{e}}{\left|\mathcal{E}_{o}^{0}\right|} \]
对于item而言:
\[ \mathrm{e}_{v}^{(\text {origin})}=\frac{\sum_{\mathrm{e} \in\{\mathrm{e} \mid(\mathrm{e}, v) \in \mathcal{A}\}} \mathrm{e}}{|\{\mathrm{e} \mid(\mathrm{e}, v) \in \mathcal{A}\}|} \]
\[ \mathcal{T}_{v}=\left\{\mathrm{e}_{v}^{(\text {origin})}, \mathrm{e}_{v}^{(0)}, \mathrm{e}_{v}^{(1)}, \ldots, \mathrm{e}_{v}^{(L)}\right\} \]
对于user而言:
\[ \mathcal{T}_{u}=\left\{\mathrm{e}_{u}^{(0)}, \mathrm{e}_{u}^{(1)}, \ldots, \mathrm{e}_{u}^{(L)}\right\} \]
Model Prediction Layer
Sum aggregator:将上一个模块的每一层向量直接相加
\[ \operatorname{agg}_{s u m}^{(o)}=\sigma\left(\mathrm{W}_{a} \cdot \sum_{e_{o} \in \mathcal{T}_{o}} \mathrm{e}_{o}+\mathrm{b}_{a}\right) \]
Pooling aggregator:去上一模块中所有层的向量中每一维度选取最大的
\[ a g g_{\text {pool}}^{(o)}=\sigma\left(\mathrm{W}_{a} \cdot \text {pool}_{\max }\left(\mathcal{T}_{o}\right)+\mathrm{b}_{a}\right) \]
Concat aggregator:将每一层向量进行拼接
\[ a g g_{\text {concat}}^{(o)}=\sigma\left(\mathrm{W}_{a} \cdot\left(\mathrm{e}_{o}^{\left(i_{1}\right)}\left\|\mathrm{e}_{o}^{\left(i_{2}\right)}\right\| \ldots \| \mathrm{e}_{o}^{\left(i_{n}\right)}\right)+\mathrm{b}_{a}\right) \]
点击率的预测函数:
\[ \hat{y}_{u v}=\mathrm{e}_{u}^{\top} \mathrm{e}_{v} \]
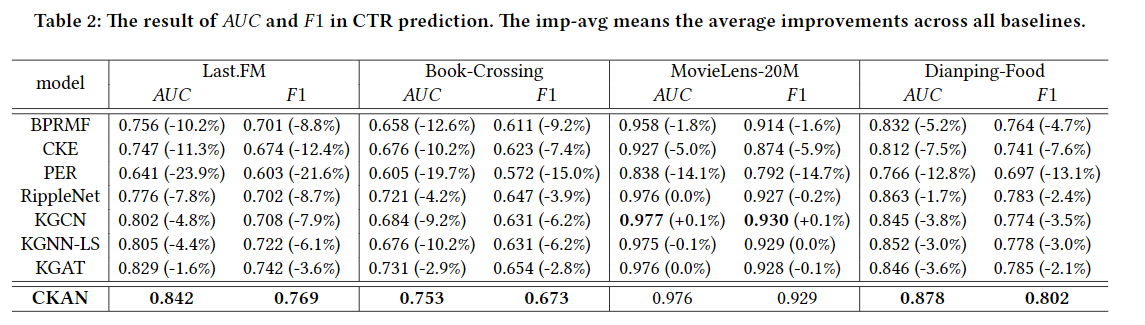
实验结果
(CKAN)Collaborative Knowledge-aware Attentive Network for Recommender Systems 论文笔记