实体消歧(Entity Disambiguation)
为了将新闻标题中的实体与知识图谱中的实体相对应,我们需要先进行实体识别(NER),再进行实体与知识图谱的映射。在这个过程中受导师指点,需要考虑实体消歧(Entity Disambiguation)的问题。因此进行调研。
对于实体消歧问题的描述
在一段文本中,由于文本和语言的多态性,一个语言字段在不考虑上下文的情况下可能对应多个实体,为了将文中的实体与知识图谱中相应的实体正确对应,提出了实体消歧问题。
注:在文本中需要与知识图谱中的entity相对应的文字段称为mention,与mention相对应的entity称为referent entity
实体链接的步骤
一共分为两个步骤:
- 对于每一个mention产生一个候选实体集(candidate),实体集中的实体全部来自于知识图谱
- 对于候选实体集中的实体进行实体消歧,通过排序选出相关度最高的那个实体作为mention的对应实体
相关论文
| 题目 | 时间 | 会议 |
|---|---|---|
| Collective Entity Linking in Web Text: A Graph-Based Method | 2011 | SIGIR |
| NeuPL | 2017 | CIKM |
| Pair-Linking for Collective Entity Disambiguation: Two Could Be Better Than All | 2018 | TKDE |
Collective Entity Linking in Web Text: A Graph-Based Method
之前的做法:通过wiki中的对于entity的描述,提取出相应的实体特征;再从mention的上下文中提取出关于mention的特征,对两者之间进行相似度匹配
创新点
设计了全局协同推理方法Collective Entity Linking,如下图例子所示:
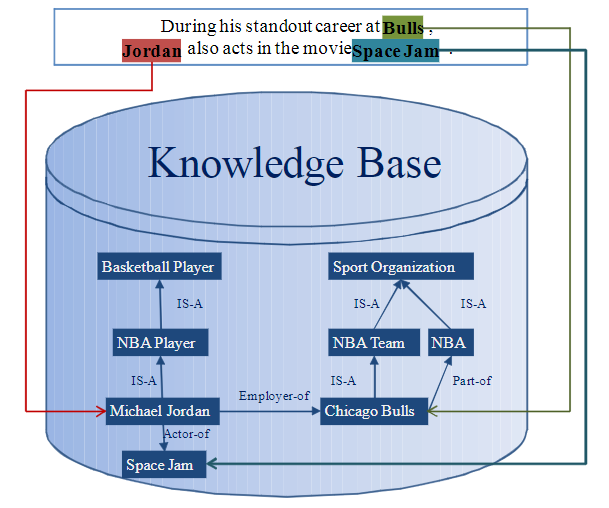
即认为单独只依赖上下文standout career at Bulls, [] also acts in the movie无法直接推断出Jordan就是Michael Jordan,需要借助其他的mention对应的entity,即Chicago Bulls and Space Jam来进行推断,此种方法称为协同实体链接。
方法
对于文本During his standout career at Bull, Jordan also acts in the movie Space Jam. 构建Referent Graph,如下所示:
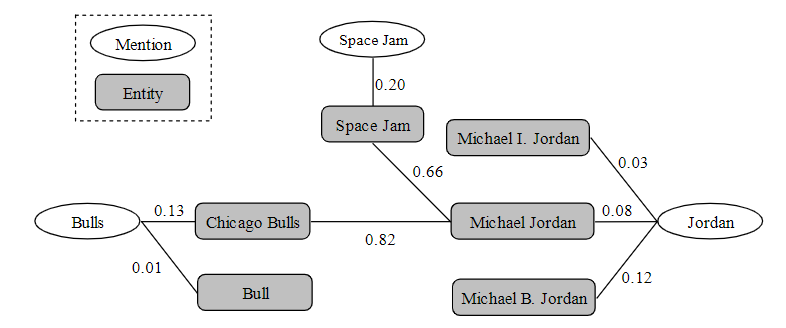
图中包含两种关系,即
- Local Mention-to-Entity Compatibility: mention与entity之间的连接
- Semantic Relation between Entities: entity之间的连接
NeuPL: Attention-based Semantic Matching and Pair-Linking for Entity Disambiguation
Intro
本篇论文所需要解决的两个问题是:
- 充分利用上下文信息来消除歧义
- 增强linked entity之间的一致性
创新点
目标函数:本文将目标函数拆成两个部分(模型)进行优化,即:
local model
作用及含义:根据mention的context来推断mention与哪一个entity相对应,计算得到Local confidence or local score \(\phi\left(m_{i}, t_{i}\right)\)反映了\(m_{i} \longmapsto t_{i}\)的概率
现存的方法:用DNN对mentions的context进行建模,此种方法存在一些问题,没有充分利用local context的信息,即:
- 上下文中可能包含多个mention,DNN无法确定应该关注于哪一个mention
- 忽视了上下文中单词间的顺序
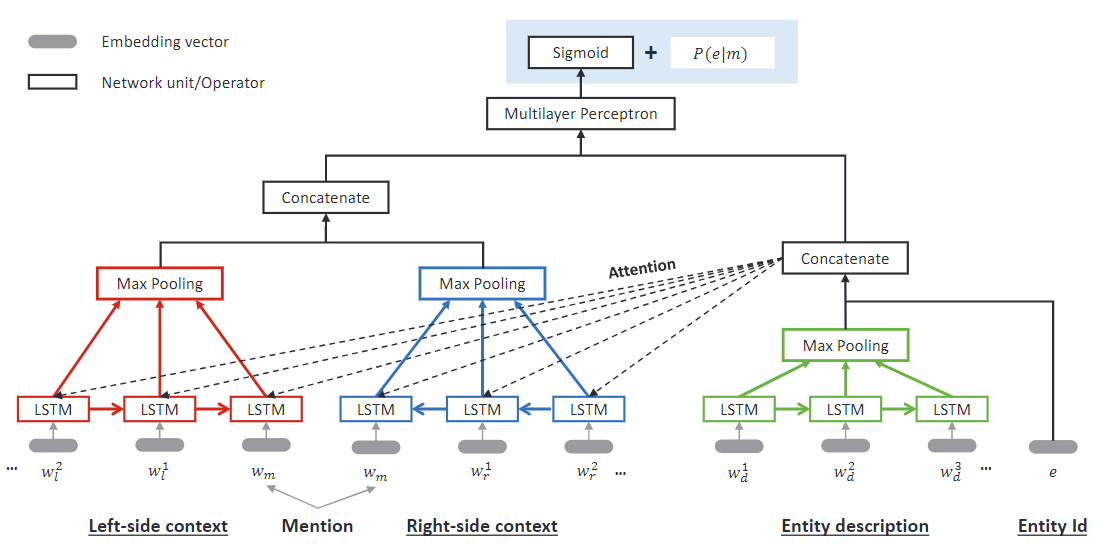
本文的改进:
- 通过两个LSTM来学习目标mention两侧的上下文信息
- 同时为了消除上下文的噪音以及学习对于不同mention的权重,引入了attention机制来提取信息
具体模型如下所示:
global model
作用及含义:在一篇文章中通过多个实体间的关系来确定待确定的实体的对应
传统的方法:
构建整篇文章的指代实体图(Referent Graph),传统的collective entity linking方法在图中实体个数过多时会消耗过多的计算时间。
同时,也不是一篇文章中的所有实体都可以进行相互推断,比如
The Sun and The Times reported that Greece will have to leave the Euro soon.这句话中的关系如下: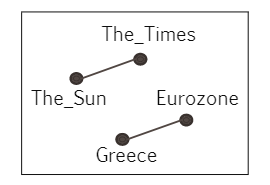
观察发现,并不是所有实体间都有联系
本文的改进:论文中提出了Pair-Linking (PL)算法,特点是,只使用一次迭代便可以完成一篇文章中所有的mentions之间的collective linking,具体的做法见下面这篇文章中介绍
Pair-Linking for Collective Entity Disambiguation: Two Could Be Better Than All

2-4行:计算任意两个mention对应的的candidate entity set之间的最小语义相似距离(构建图中的边)
7-9行:类似Kruskal算法,每次选取confident最高(语义相似距离最小)的边
10-13行:一旦一个candidate entity set中的entity被选中,则此set中的其他entity被从图中抹去,更新剩余的集合间语义距离
可以图示如下:

算法停止时间:所有的实体集中都有一个实体被选中,不需要形成最小生成树
实体消歧(Entity Disambiguation)