Bert模型 学习笔记
BERT之前
ELMo的提出
ELMo属于一种word embeding,由于同一个单词可能有不同的含义,因此对于同一个单词应该有多重向量来表示。具体的应用在于,先观察整个句子,然后再为每个单词生成相应的embeding。
具体而言是将整个句子的初始embeding过一遍预训练的Bi-LSTM(language modeling)——本质上而言,也是在句子单侧的编码,为每个单词生成相应的embeding。如下图所示:

随后将这些隐藏层(包括初始的embeding)通过每种方式结合在一起
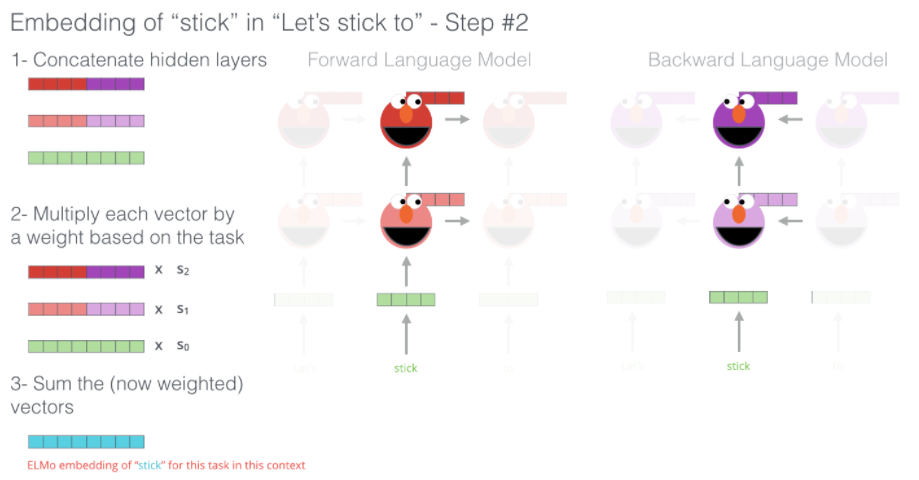
最后得到相应的embeding,如上图湖蓝色所示
ULM-FiT:明确的将迁移学习引入NLP
ULM-FiT介绍了一个语言模型和一种将语言模型进行微调以适应各种其他任务的方法
Transformer:超过LSTMs
在处理长序列方面的能力超过了LSTM
OpenAI Transformer: Pre-training a Transformer Decoder for Language Modeling
将Transformer的Decoder改造为可以与训练的语言模型,The OpenAI Transformer通过7000本书来实现预训练
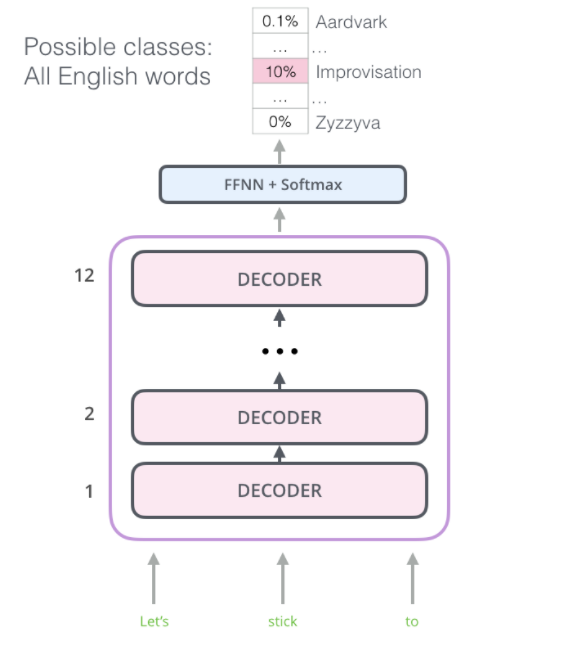
迁移至下流任务
BERT
BERT:From Decoders to Encoders
目标:改变Transformer模型,使其能够学习句子双侧的序列信息
使用Transformer的多层Encoder部分(而不是Decoder部分)来学习句子中词向量的表示,提出BERT的论文的全名是BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,从其名字可以看出模型的特点:Pre-training、Deep、Bidirectional、Transformer、Language Understanding
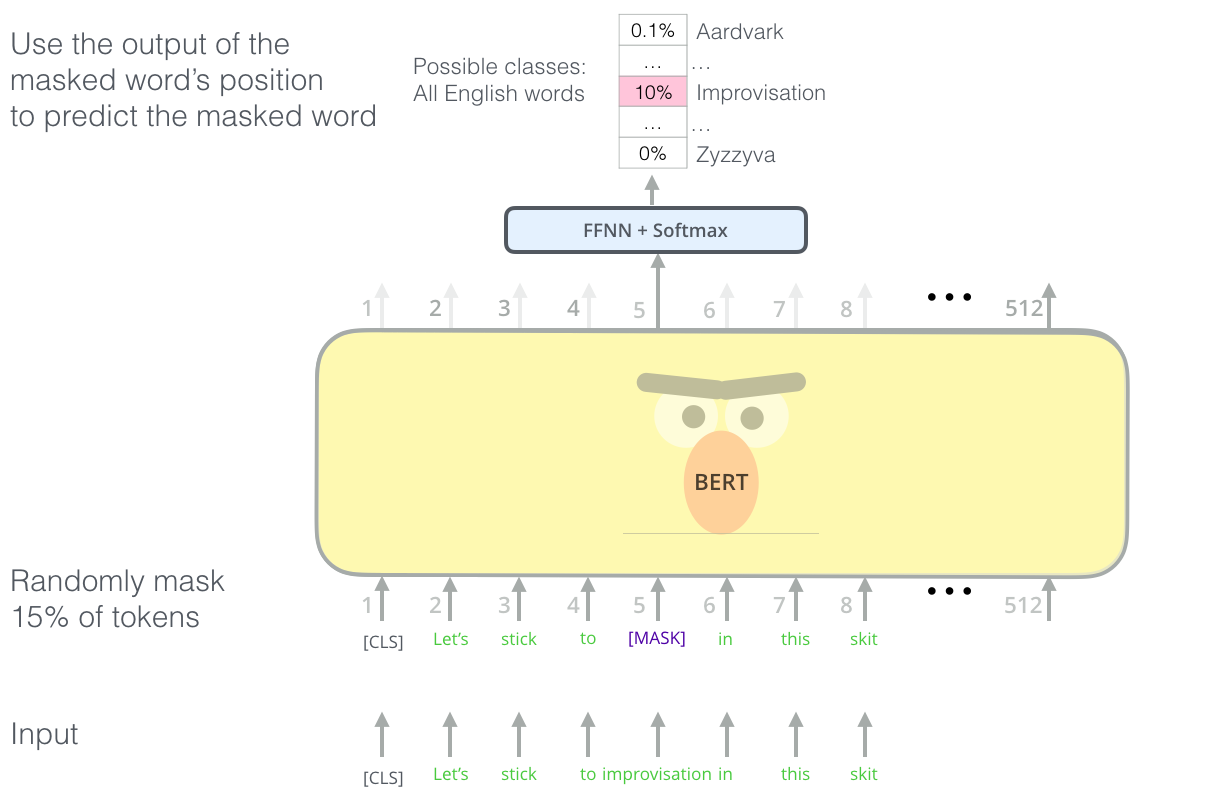
由于语言模型的特点是:已知前N个词来预测第N+1个词,因此以往的语言模型均是单向学习的语言模型。而BERT提出遮蔽语言模型(masked language model,MLM),即在训练时随机MASK掉15%的单词,对于一个被MASK的单词:
- 有80%的概率用“[mask]”标记来替换
- 有10%的概率用随机采样的一个单词来替换
- 有10%的概率不做替换(虽然不做替换,但是还是要预测哈)
具体模型如下:
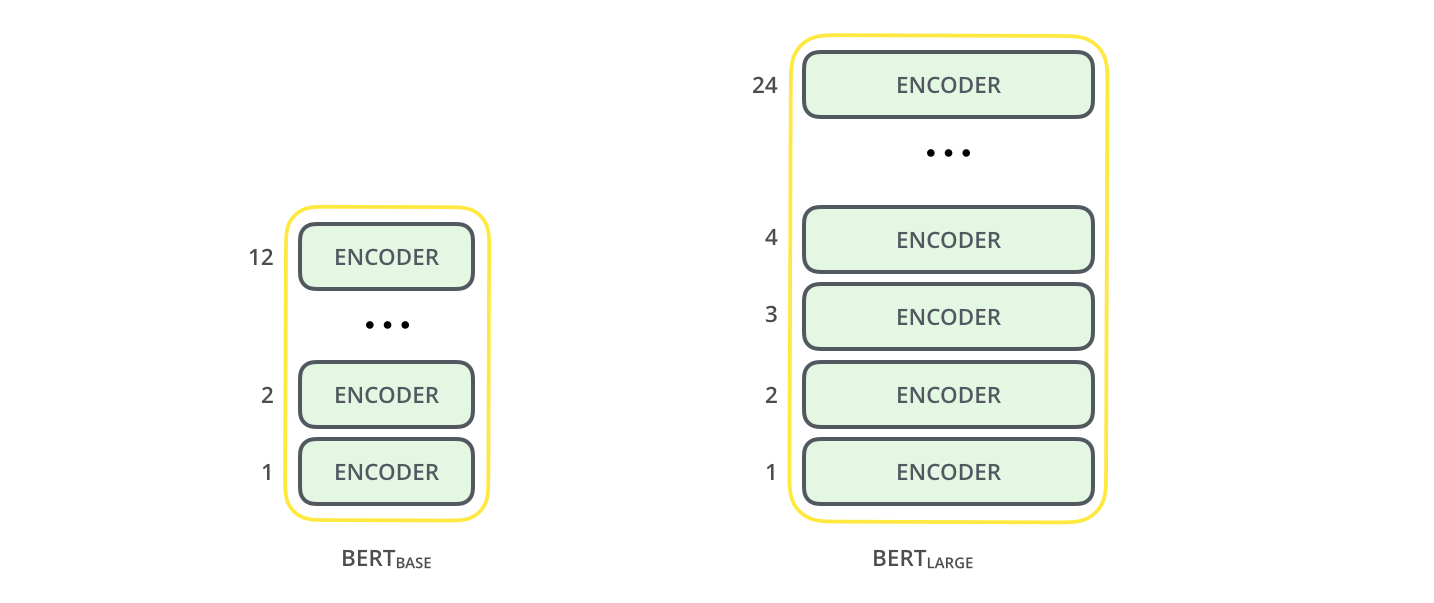
即进行多层Transformer中的Encoder的堆叠,论文中的模型参数为:
BERTBASE (L=12, H=768, A=12, Total Parameters=110M)
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M).
BERT模型的训练特点
共分为两步进行训练:
对于被MASK的词汇进行预测:进行语言模型的学习
进行下一句预测:学习句子间的关系
其中[seq]为句子分隔符,每次输入两个句子,训练模型用来判断第二个句子是否是第一个句子的下一个
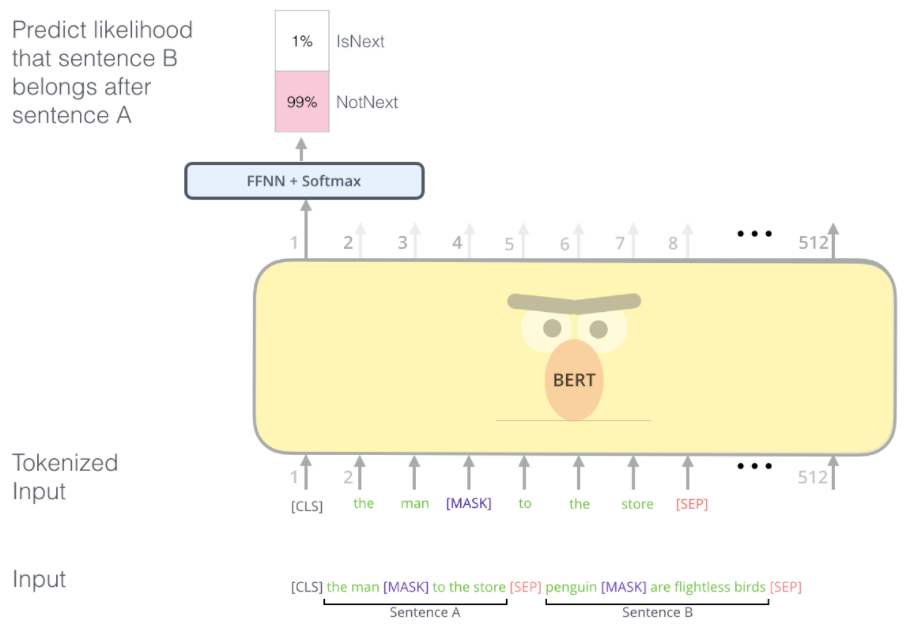
此后得到的模型为预训练的模型,可以作为后期词向量embeding的生成器
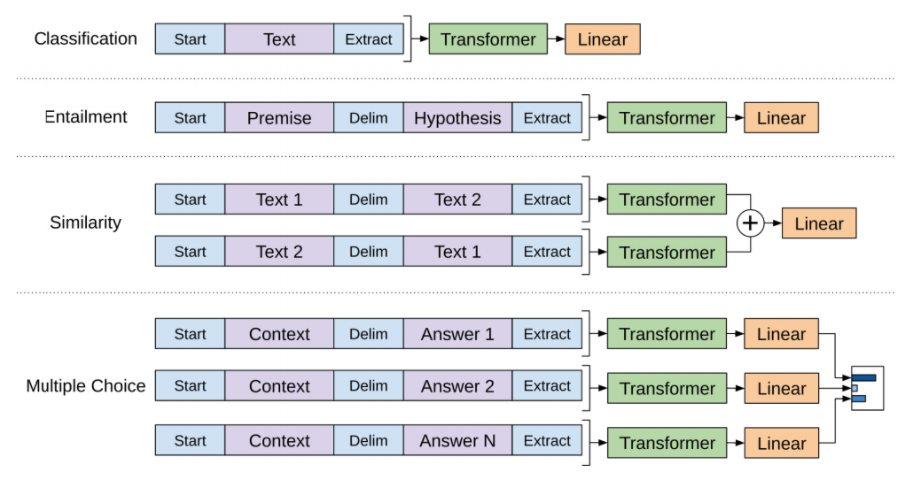
BERT模型的应用
Sentence Classification
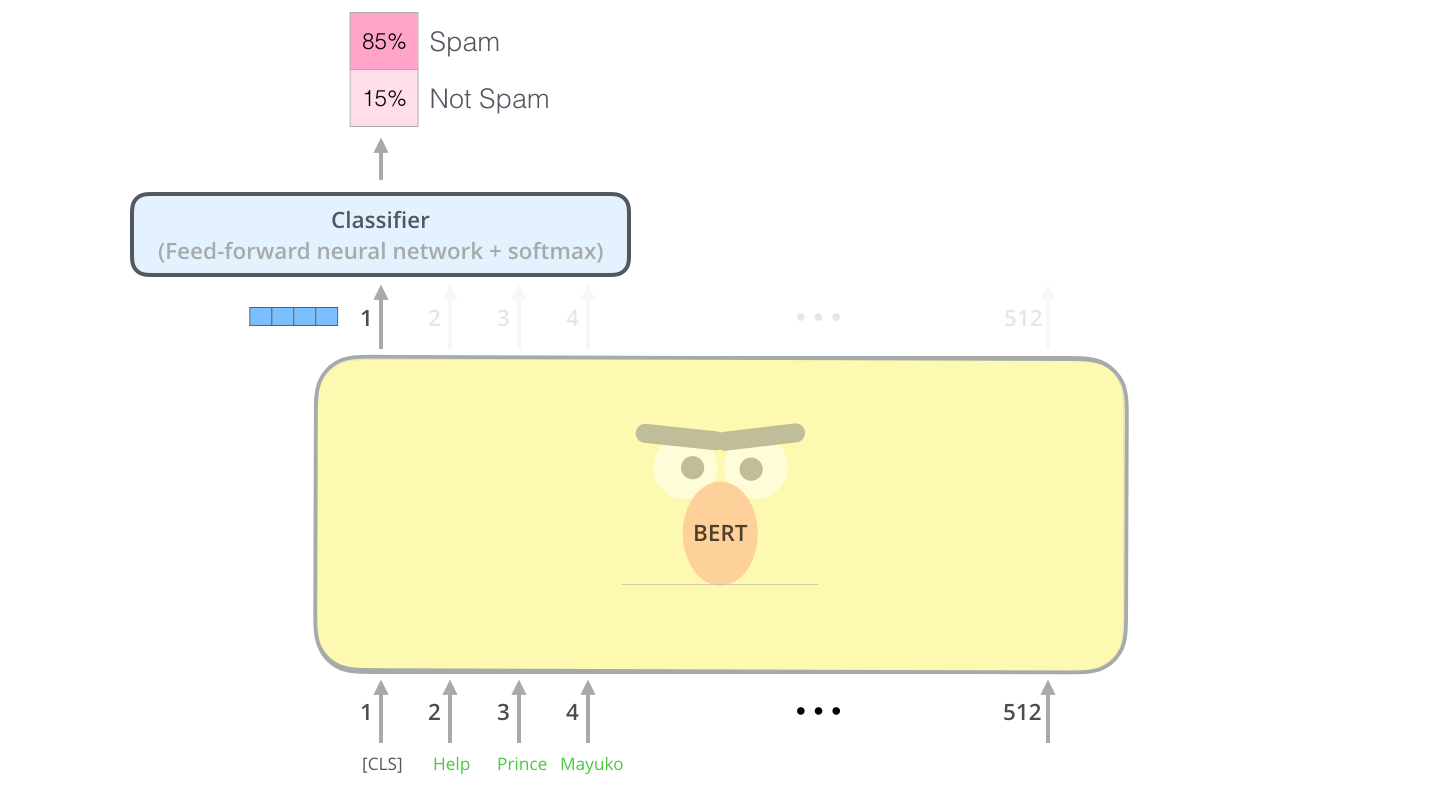
在句子前面加入[CLS]标致,通过最后一层输出的[CLS]的向量表示来进行句子分类。因为该向量已经学得了整个句子的信息。因此像RNN一样不用考虑其他位置单词的信息。直接判断即可
Reference
[1] The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
[2] NLP的游戏规则从此改写?从word2vec, ELMo到BERT
[4] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding