transformer模型 学习笔记
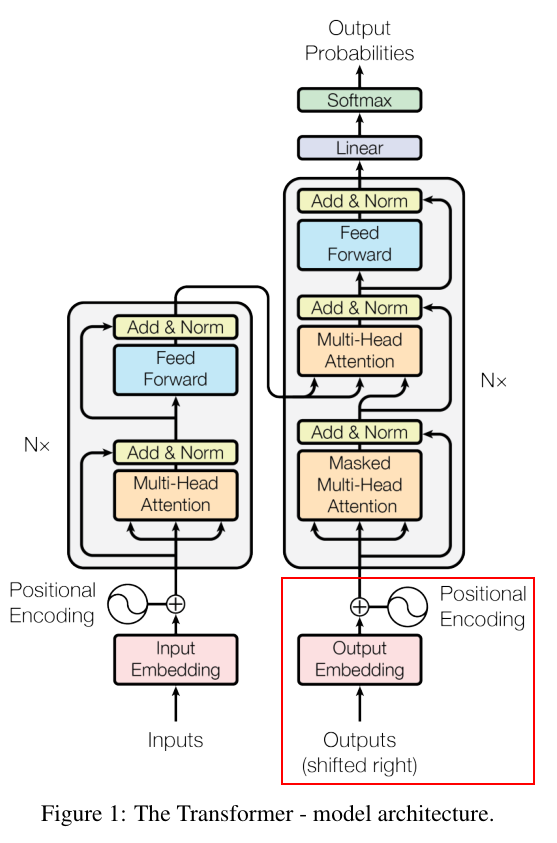
整体架构
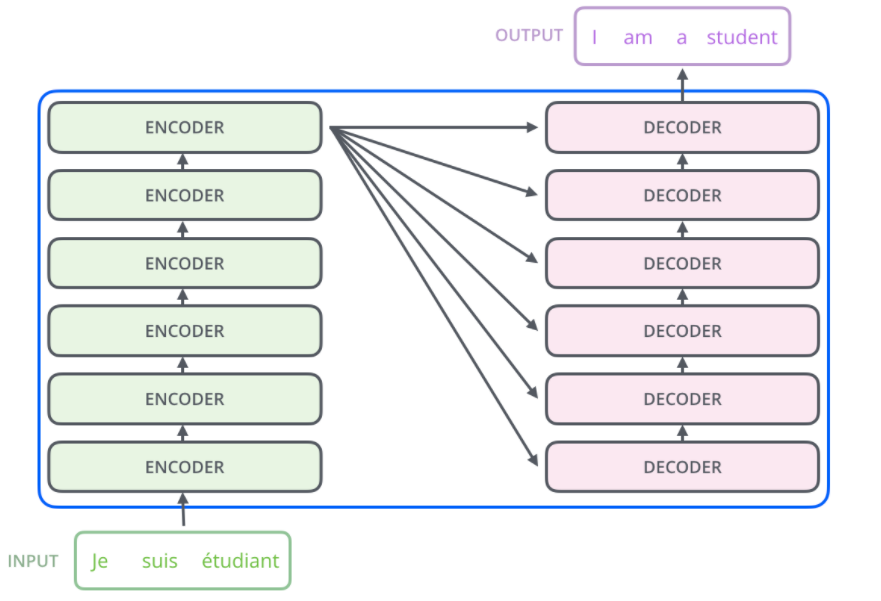
- encoders中多个堆叠的encoder之间不共享参数
- encoder的个数与decoder的个数相同
其中每个encoder的内部构造如下所示:
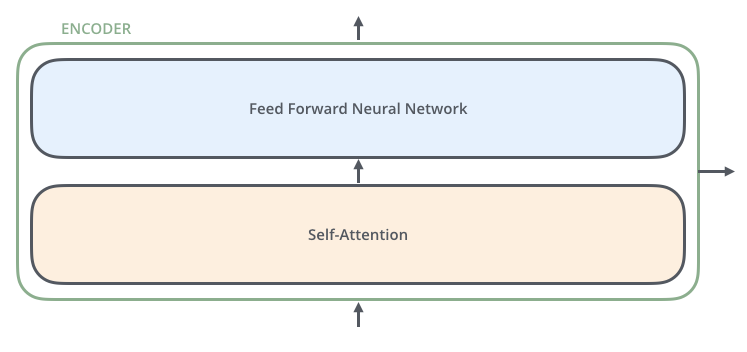
- self-encoder的作用,帮助编码器在编码特单词时留意其他的单词
其中decoder和encoder之间的连接如下:
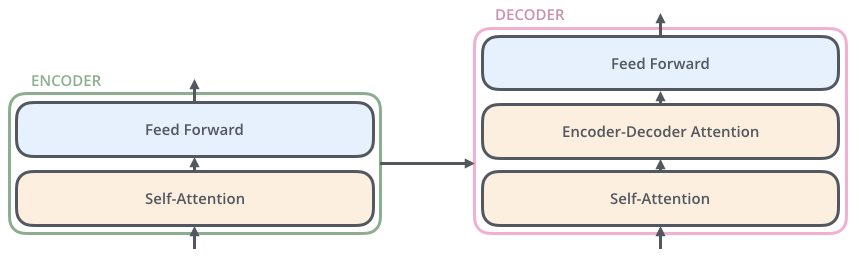
transformer的主要优点在于其并行计算的能力,主要在于feed forward层面
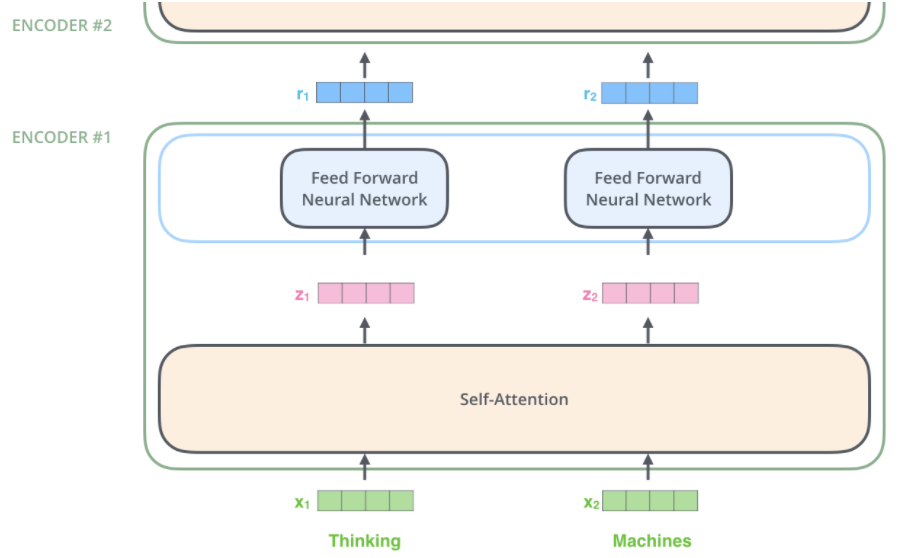
- 通过self-attention之后的词向量,分别经过相同的feed forward network(参数相同)因此可以并行
Encoder解读
self-attention的作用机制
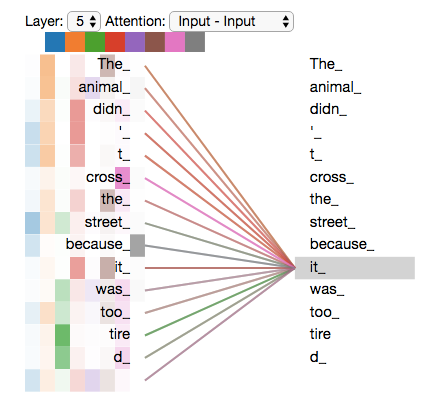
对于句子“The animal didn't cross the street because it was too tired.”,利用self-attention可以将it与the animal产生关联,即通过句子中的其他词更好的解释当前词

Self-attention is the method the Transformer uses to bake the “understanding” of other relevant words into the one we’re currently processing.
self-attention详解
此处介绍的是Encoder中的self-attention,不同于Decoder
对于其中一层的self-attention而言:
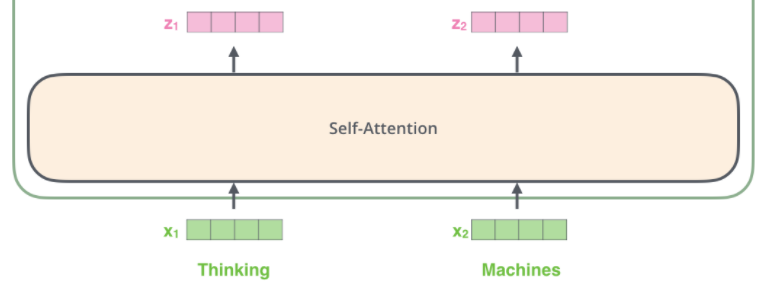
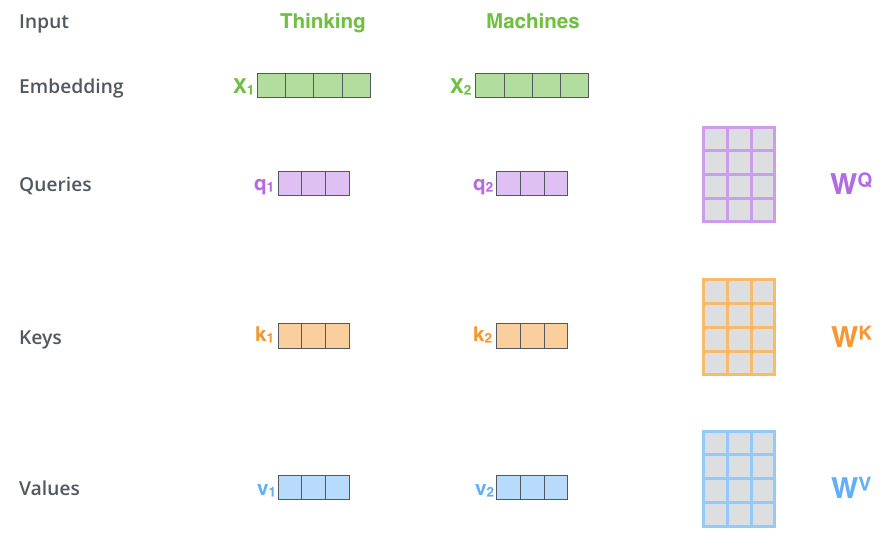
从向量X到向量Z的计算步骤为:
初始化三个权重矩阵\[ W^Q \],\[ W^K \],\[ W^V \](这三个权重矩阵在训练过程中参数会得到训练,在代码中表示为经过了三个线性层),分别将单词的embedding与这三个矩阵相乘,得到每个embedding对应的Query,key,value向量
这一步的主要内容是来计算得分,即当前词和所输入句子中其他词相关性的得分。计算方法为:假设当前单词所处的位置为#1,计算其与#2位置的单词的相关性的方法为:用\[q_1\]和\[k_2\]进行点乘。举个栗子而言:假设输入的句子为
“thinking machines”,其计算如下: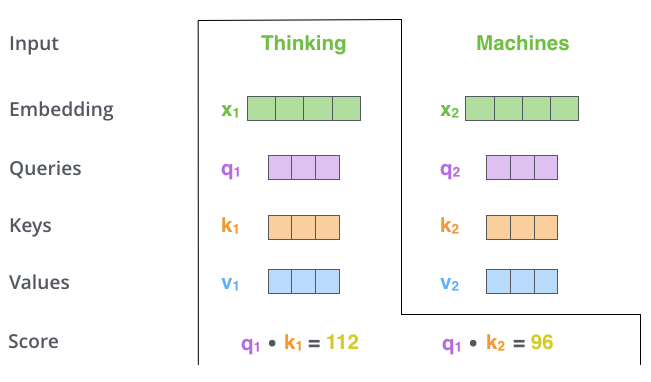
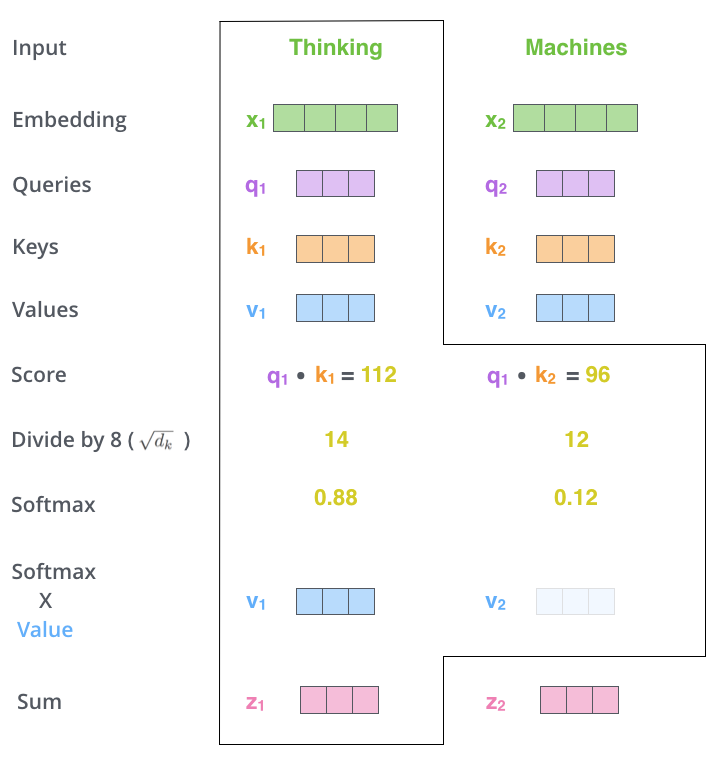
将得分除以8(key vector维度的平方根,paper中定义为64维),目的是为了维持更稳定的梯度。
将当前词与每个单词的得分通过softmax函数处理

根据#1,#2位置的softmax的值,计算加权的#1,#2位置单词对应的结果向量。self-attention执行完毕,接下来将向量送入前馈网络即可
multi-headed attention机制详解
本质是每次计算self-attention模块时,使用多组Query/Key/Value权重矩阵(Transformer使用的是8个),每一组矩阵代表一个头
执行结果如下:
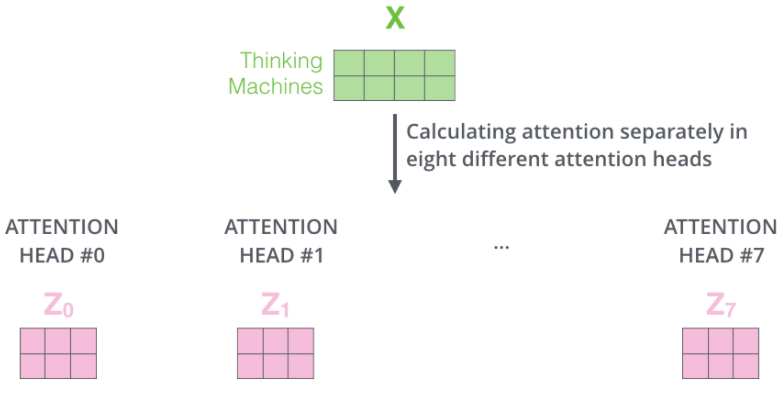
由于feedforword模块只需要输入一个矩阵,因此执行如下操作:

多头注意力机制的可视化:我们可以看出每个attention关注的侧重点不同
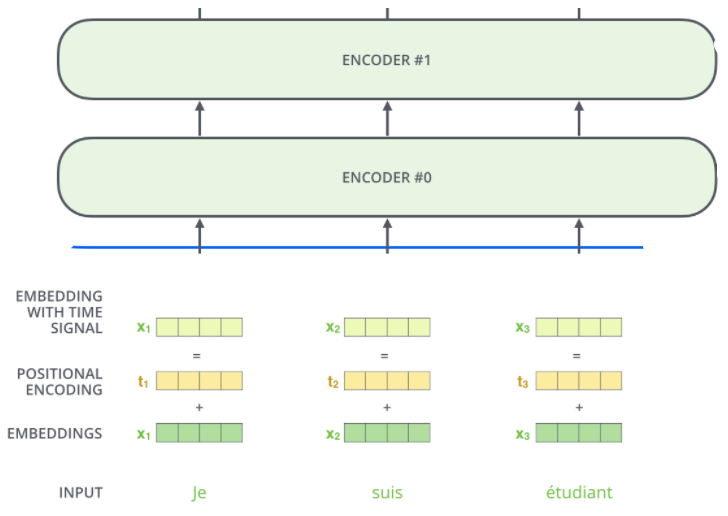
对于单词的embedding加入位置和序列信息
之前值注重于考虑词与词之间的关联性信息,对于输入序列的单词在编码时没有考虑其位置信息,在此处加以处理
通过向量,表示出位置和序列信息,与原有信息进行加和。具体如下图所示:
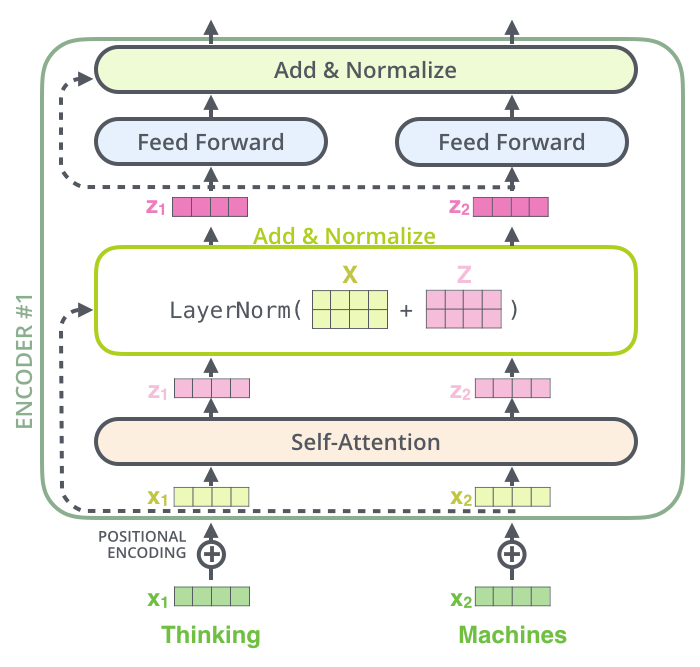
残差连接
其可视化结果如下,在进行残差连接后,经过一个LayerNorm层
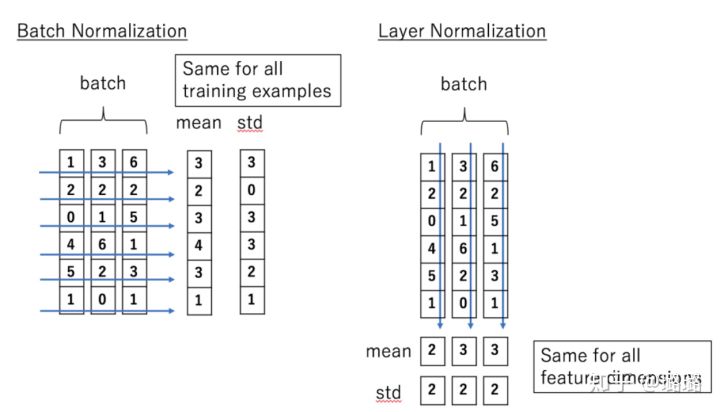
关于LayerNorm和BatchNorm之间的区别
Decoders解读
Decoders中含有和Encoders中数量相同的encoder,每一个Decoder的结构包含三层,分别是:self-attention,Encoder-Decoder attention,Feed forward层
其图示如下:
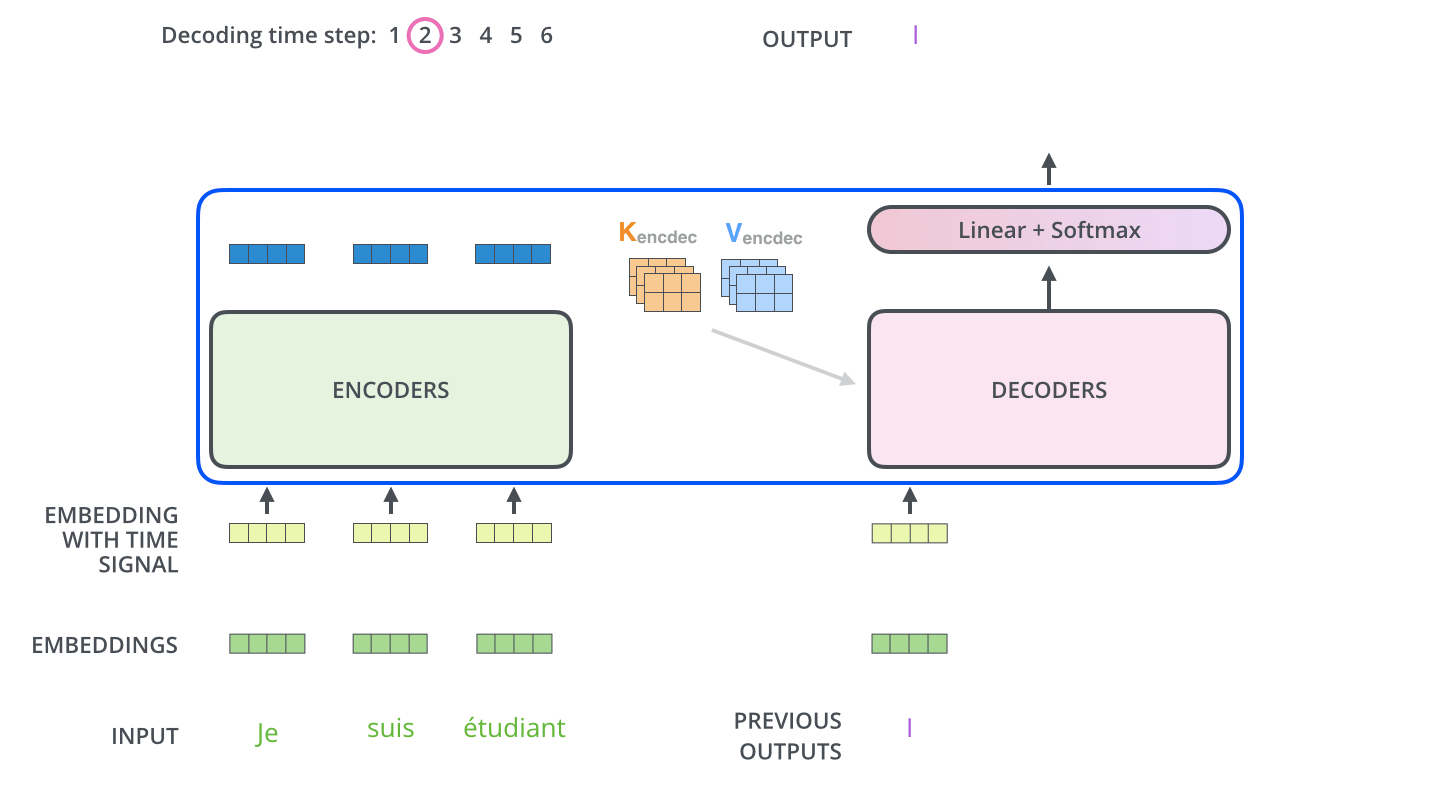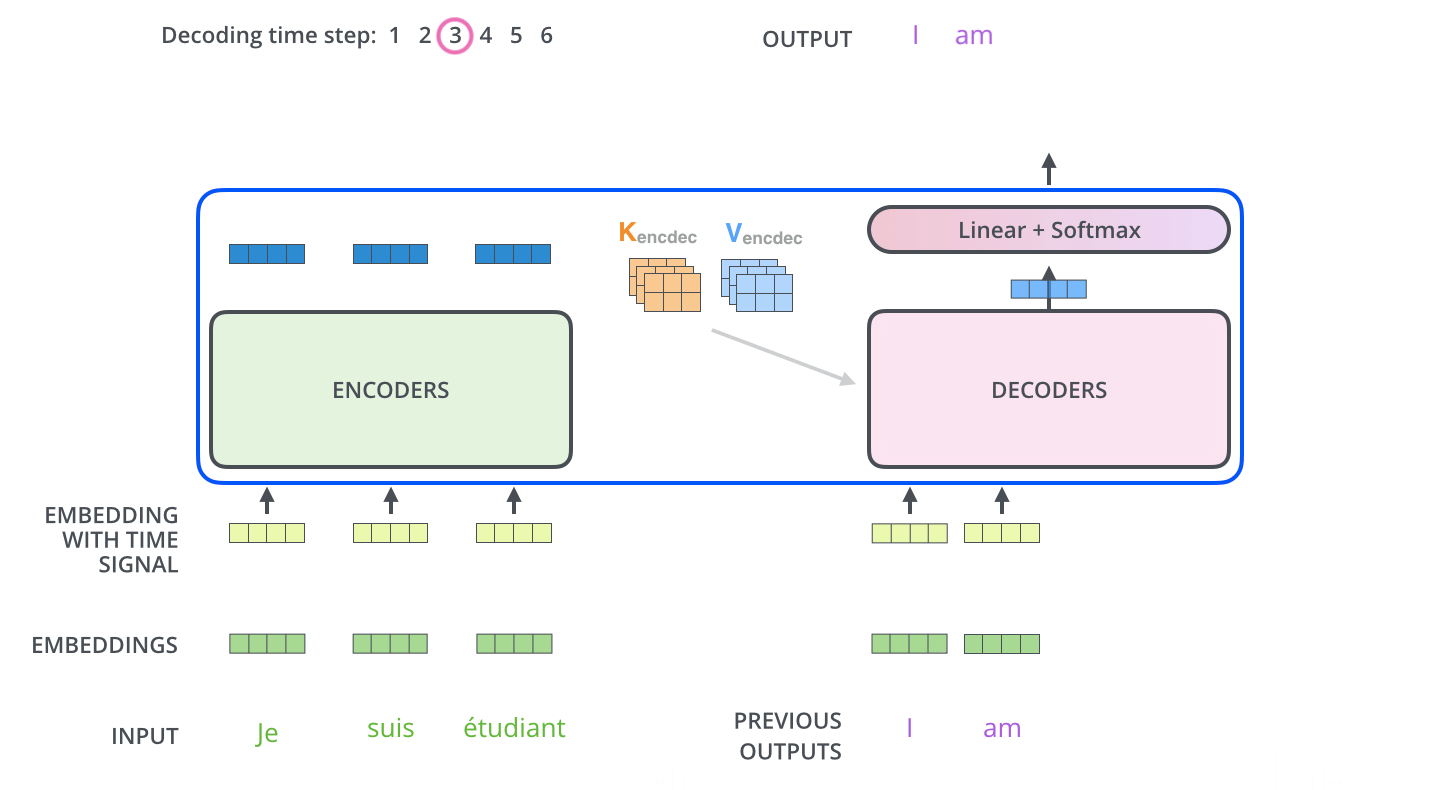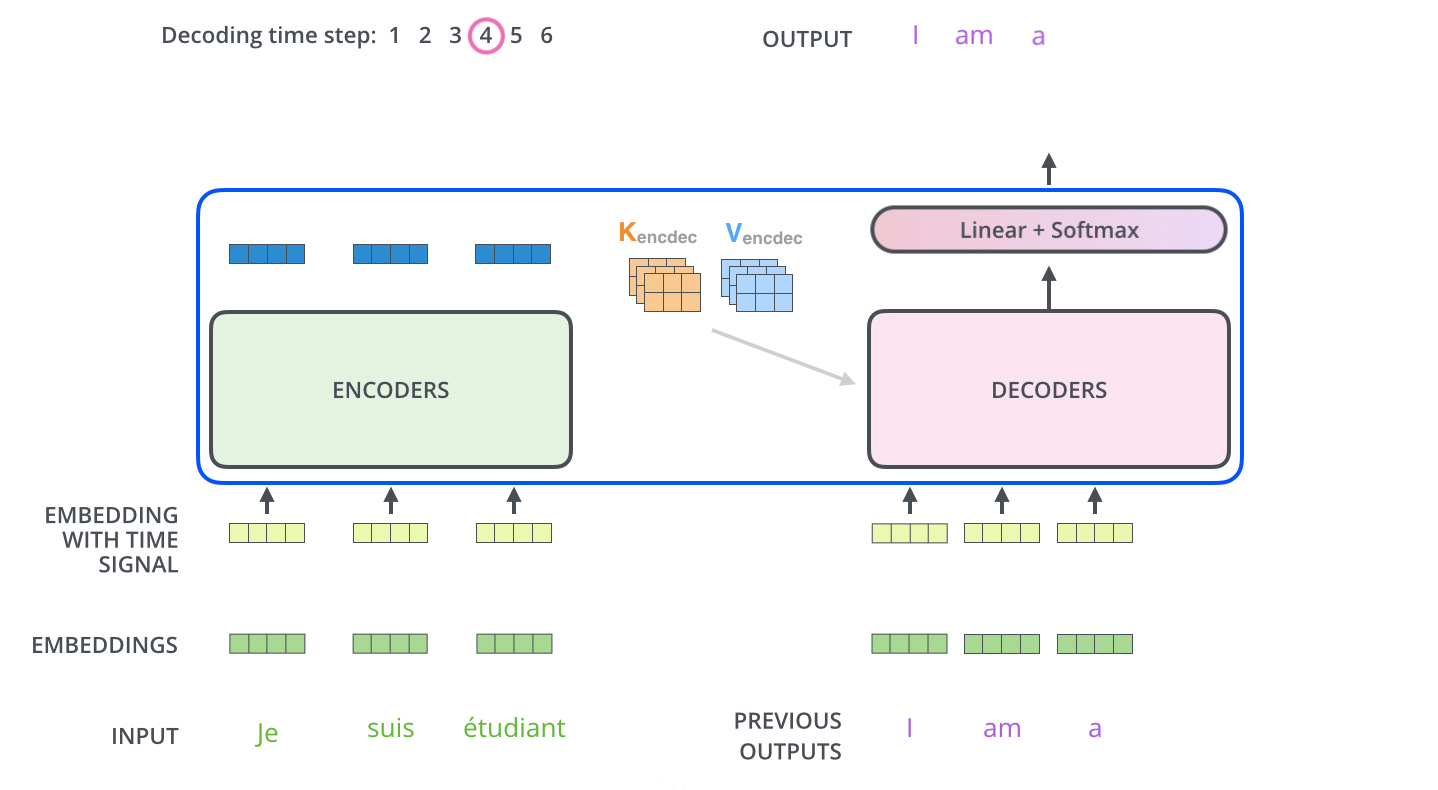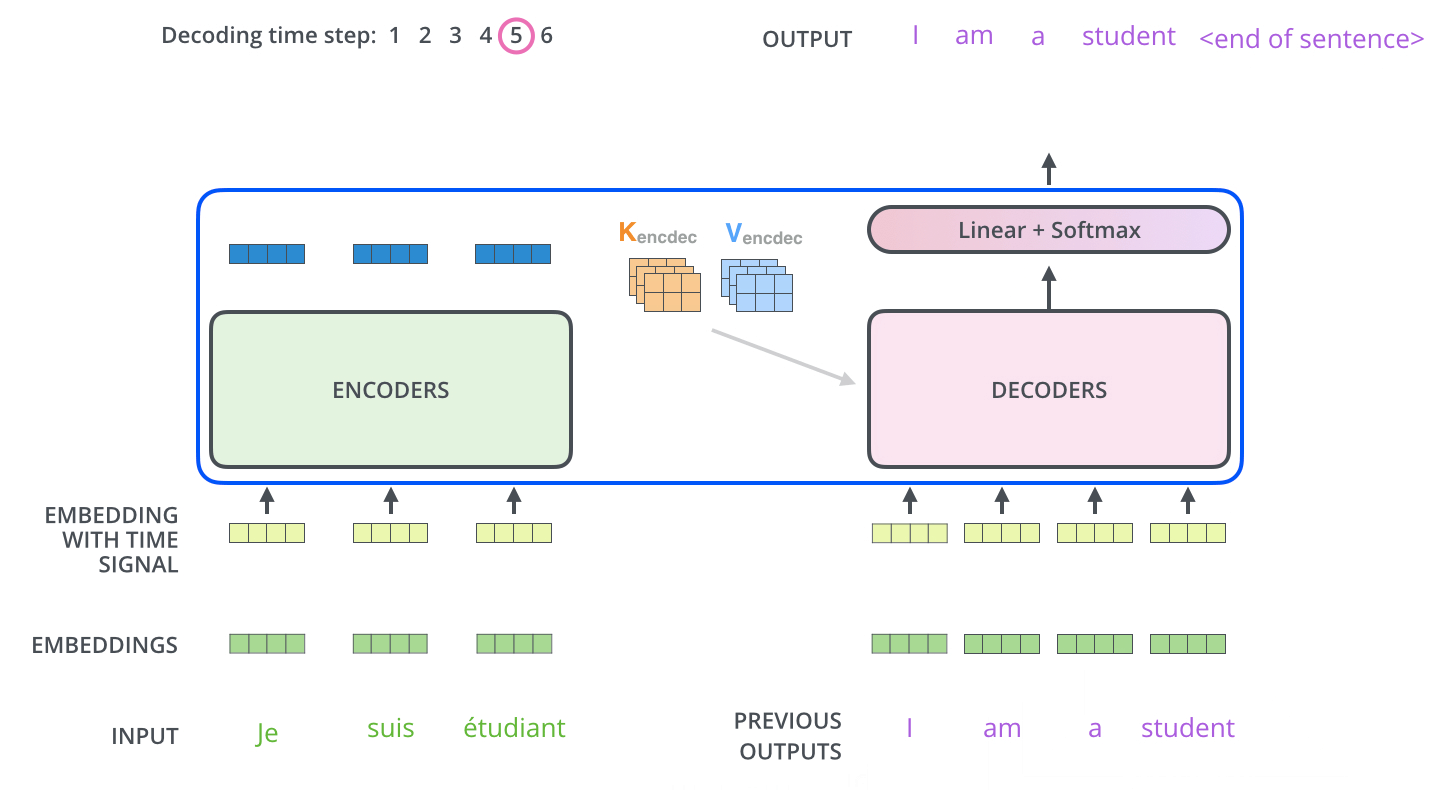
Decoders中每一个Decoder的输出会传入上一层作为输入;第一层decoder之前也是加入位置信息的embeding层,如下图所示:
Decoders是自回归的,意味着每次Decoders均只预测一个单词,每一次预测的输出都会累加起来重新作为对于下一次预测的输入(此处可以将Decoders看做一个RNN,具体如下图所示)——在输出停止符号<end of sentence>后停止迭代
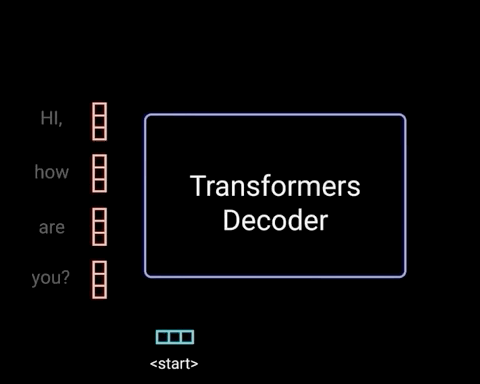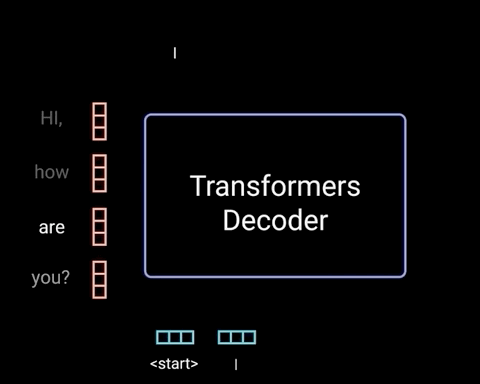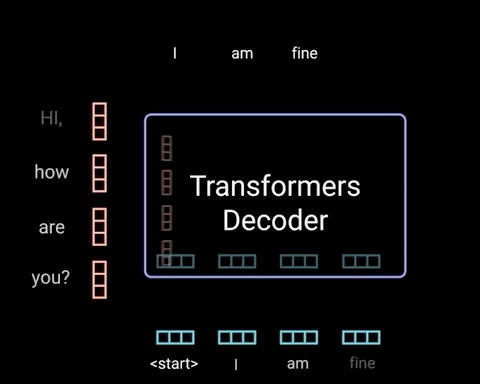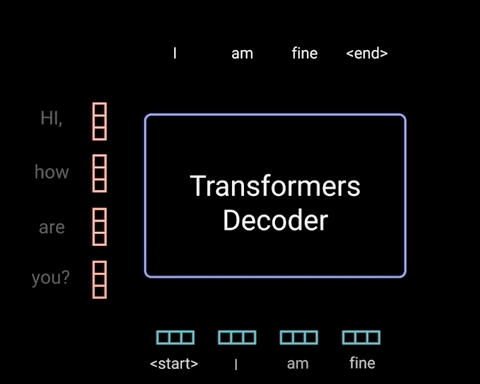
比如:输入<start>得到“I”
Decodrs的输入 Decoders的输出 <start> I <start> I am <start> I am fine <start> I am fine <end> Decoder中的self-attention不同于之前介绍的encoder中的self-attention,只对序列中的前面的向量计算softmax,而对后面的向量进行mask操作
Decoder和Encoder之间的合作
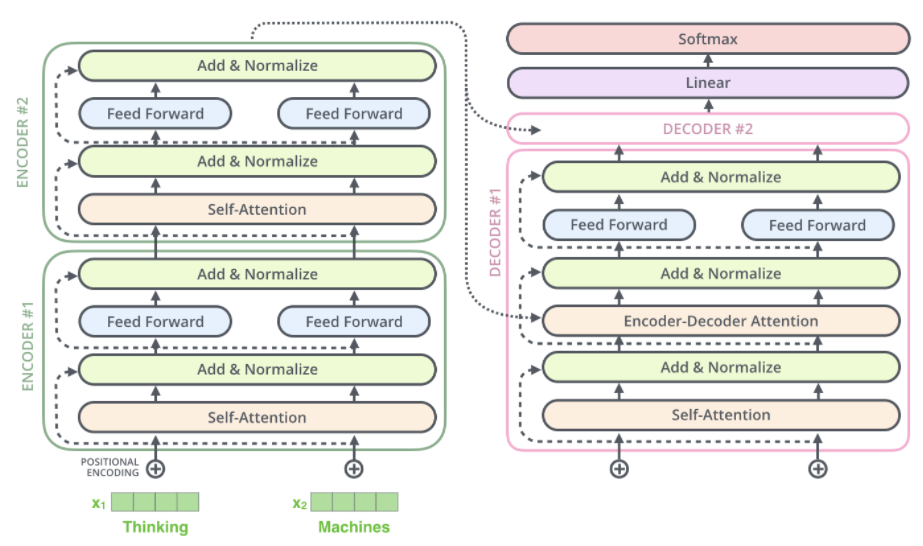
对于Encoder-Decoder attention的解读
Encoder-Decoder attention的本质还是self-attention,分别将encoder输出的序列经过线性变换得到k和v序列,将第一层经过self-attention层输出的向量作为q向量序列
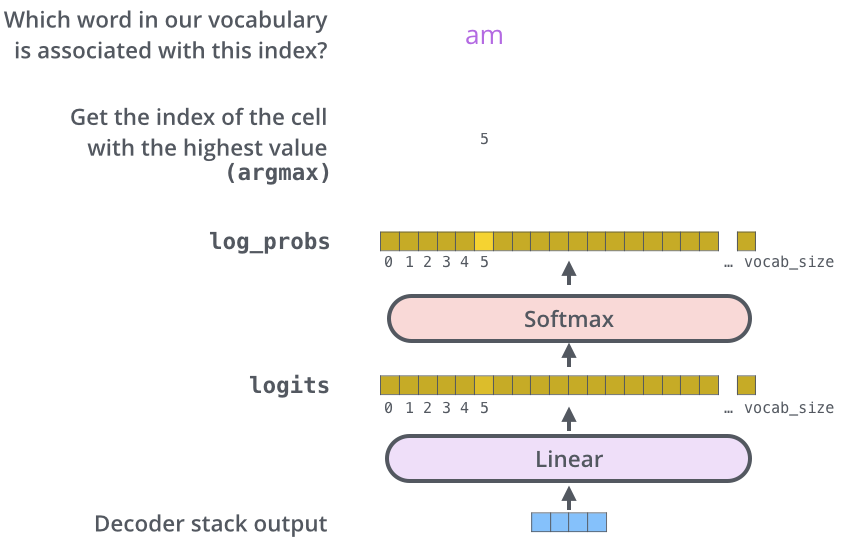
对于最后的Linear and Softmax Layer的解读
主要作用在于将输出的向量转化为对应的单词
Linear Layer是一个全连接网络,用于将Decoders输出的向量映射到词汇表相应的维度,得到logits向量(即进行归一化前的对应到各个词的可能得分)
Softmax layer则将各个维度对应的得分映射到 (0,1] 之间的概率,对应概率最高的维度对应的单词即为目标单词
参考及图片来源
[1] Illustrated Guide to Transformers- Step by Step Explanation
[2] The Annotated Transformer harvard的源码解读
transformer模型 学习笔记