chap 9-Relevance feedback and query expansion
相关反馈及伪相关反馈
属于查询优化的局部方法,在一个查询的初始返回结果的基础上进行完善,使得再次返回的结果得到优化
相关反馈的主要思想:在信息检索的过程中通过用户交互来提高最终的检索效果。让用户来判断相关性
具体过程如下:
- 用户提交一个简短的查询
- 系统返回初次检索结果
- 用户对部分结果进行标注,将它们标注为相关或不相关
- 系统基于用户的反馈计算出一个更好的查询来表示信息需求
- 利用新查询系统返回新的检索结果
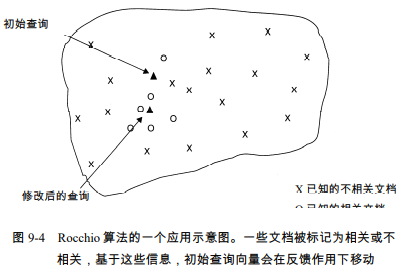
Rocchio 相关反馈算法
基本原理:假定我们要找一个最优查询向量\(\vec{q}\) ,它与相关文档之间的 相似度最大且同时又和不相关文档之间的相似度最小
若\(C_{r}\)表示相关文档集,\(C_{n r}\)表示不相关文档集,那么我们希望找到的最优的\(\vec{q}\) 是:
另一种定义为:
增加权重后为:
其中定义\(C_{r}\)为已知的相关文档集,\(C_{n r}\)为已知的不相关文档集
影响相关反馈的因素
初始查询时出问题:
- 拼写错误,可通过拼写校正技术来解决
- 跨语言IR
- 用户的词汇表和文档集的词汇表不同,比如laptop和notebook computer
相关反馈方法的使用条件:
理想条件下,所有相关文档中的词项分布应该与用户标出的相关文档中的词项分布相似,而同时所 有不相关文档中的词项分布与相关文档中的词项分布差别很大。如果相关文档包括多个不同子类,即它们在向量空间中可 以聚成多个簇,那么 Rocchio 方法效果会不太好
对于相关反馈策略的评价
- 首先计算出原始查询 \(q_{0}\) 的正确率—召回率曲线,一轮相关反馈之后,我们计算出修改后的 查询 \(q_{m}\) 并再次计算出新的正确率—召回率曲线。这样,反馈前与反馈后我们都可以在所有文档 上对结果进行评价,然后直接进行比较
- 利用剩余文档集(residual collection,所有文档集中除去用户判定的相关文档 后的文档集)对反馈后的结果进行评价。这种思路看上去更具现实性。不过,性能的度量结果 往往低于原始查询的结果。
伪相关反馈
伪相关反馈(pseudo relevance),也称为盲相关反馈(blind relevance feedback),提供了一 种自动局部分析的方法。它将相关反馈的人工操作部分自动化,因此用户不需要进行额外的交 互就可以获得检索性能的提升。
该方法首先进行正常的检索过程,返回最相关的文档构成初始集,然后假设排名靠前的 k 篇文档是相关的,最后在此假设上像以往一样进行相关反馈
间接相关反馈
在反馈过程中,我们也可以利用间接的资源而不是显式的反馈结果作为反馈的基础。这种 方法也常常称为隐式相关反馈(implicit relevance feedback)。
隐式反馈不如显式反馈可靠,但是 会比没有任何用户判定信息的伪相关反馈更有用
查询扩展
属于查询优化的全局方法,在不考虑查询及其返回文档情况下对初始查询进行扩展和重构的方法
主要思想是使用同义词词典对于查询词t进行自动扩展,其中同义词词典的构建方法共有3种,即:
- 简单辅助用户进行查询扩展
- 采用人工词典的方法
- 自动构建词典的方法
chap 9-Relevance feedback and query expansion
https://xdren69.github.io/2020/09/19/information-retrieval-ch9/