chap 10-XML retrieval
XML文本的基本概念
XML文本的主要特点为:具有复杂的树形结构,属性之间还存在嵌套关系
XML文本举例:

转化为树形结构:
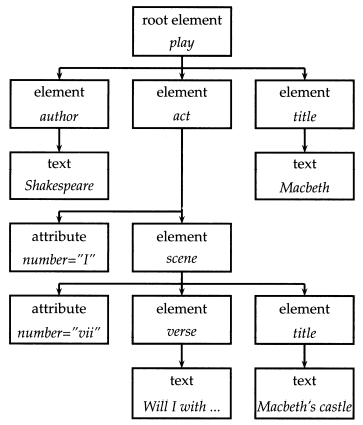
XML DOM:将元素、属性以及元素内部的文本表示成树的节点
XPath: 是XML文档集中的路径表达式描述标准,也称为XML上下文。路径上前后元素间使用”/“来分割;"//"表示中间可以插入多个元素。eg:act/scene 表示选择所有父节点为 act 元素的scene元素;plan//scene表示选择出现在play元素下的所有scene 元素
XML检索中的挑战性问题
结构化检索中的挑战是用户希望返回文档的一部分(即 XML 元素),而不像非结构 化检索那样往往返回整个文档
选择最合适的文档部分的一个准则是:系统应该总是检索出回答查询的最明确最具体的文档部分,即返回信息需求的最小单位
该问题相对应的问题是:“对文档的哪些部分建立索引”,具体方法如下:
将节点分组
使用最大的元素作为索引单位,然后在最大的元素中寻找相关的子元素——自顶向下
先搜索最相关的子节点,然后扩展成更大的单位(父节点)——自底向上
对所有元素建立索引
由此产生的问题,即冗余性增大,同时元素间存在嵌套关系
解决方法:构造元素选择时的限制策略:
- 忽略所有的小元素
- 忽略用户不会浏览的所有元素类型(这需要记录当前 XML 检索系统的运行日志信息)
- 忽略通常被评估者判定为不相关性的元素类型(如果有相关性判定的话)
- 只保留系统设计人员或图书馆员认定为有用的检索结果所对应的的元素类型
对于剩余的冗余元素,将嵌套元素组合起来,并将查询词高亮显示来吸引用户关注相关段落
对于嵌套问题,还会引起词项统计信息的不准确,解决方法如下:
为XML的每个上下文-词项对计算idf,只考虑目标节点的父节点:比如 author#"Gates" 和 section#"Gates"
chap 10-XML retrieval
https://xdren69.github.io/2020/09/19/information-retrieval-ch10/