chap 7-Computing scores in a complete search system
- 以文档为单位的评分方法:每次计算一篇文档的得分
- 以词项为单位的评分方法:遇到每个词项时,得分能够逐渐累加
快速评分及排序
第六章介绍的是精确返回前K篇得分最高的文档的办法;此处我们开始关注非精确返回前K篇文档的方法,即前K篇返回的文档与最相关的K篇近似,但又不完全相同。同时用户感受不到返回的前K篇文档间的相关度有所降低,这样做的好处是可以降低运算的复杂度
此处介绍的算法主要包含如下的两个步骤:
- 找到一个文档集合 A,它包含了参与最后竞争的候选文档,其中\[K<|A|<<N\]。A 不必包 含前 K 篇得分最高的文档,但是它应该包含很多和前 K 篇文档得分相近的文档
- 返回 A 中得分最高的 K 篇文档
索引去除技术
- 仅考虑查询中词项idf值超过一定阈值的单词所对应的倒排记录表
- 仅考虑包含多个(K个)查询词项的文档
胜者表
胜者表(champion list),有时也称为优胜表(fancy list)或高分文档(top doc),它的基本 思路是,对于词典中的每个词项 t,预先计算出 r 个最高权重的文档,其中 r 的值需要事先给定。 对于 tf-idf 权重计算机制而言,词项 t 所对应的 tf 值最高的 r 篇文档构成 t 的胜者表
静态得分和排序
很多搜索引擎中,每篇文档 d 往往都有 一个与查询无关的静态得分 g(d)。该得分函数的取值往往在 0 到 1 之间。比如,对于 Web 上 的新闻报道,g(d)可以基于用户的正面评价次数来定义。
可将静态得分和相似度组合得出每个文档的得分,即:
\[\text { net-score }(q, d)=g(d)+\frac{\vec{V}(q) \cdot \vec{V}(d)}{|\vec{V}(q) \| \vec{V}(d)|}\]
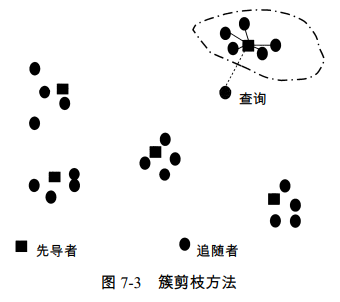
簇剪枝方法
主要原理是对所有的文本使用聚类操作,聚类操作如下:
- 从 N 篇文档组成的文档集中随机选出\[\sqrt{N}\]篇文档,它们称为先导者(leader)集合
- 对于剩余的\[N - \sqrt{N}\]篇(称为追随者,follower)每篇不属于先导者集合的文档,计算离之最近的先导者
查询操作如下:
- 给定查询 q,通过与\[\sqrt{N}\]个先导者计算余弦相似度,找出和它最近的先导者 L
- 候选集合 A 包括 L 及其追随者,然后对 A 中的所有的文档计算余弦相似度
信息检索系统的组成
此处介绍信息检索系统中常用的一些概念,即:
层次型索引
是对索引去除方法的一般化技术:例如,第 1 层索引中的 tf 阈值是 20, 第 2 层阈值是 10。这意味着第 1 层索引只保留 tf 值超过 20 的倒排记录,而第 2 层的记录只保 留 tf 值超过10的倒排记录。

查询词项的邻近性
对于检索中的查询,特别是Web上的自由文本查询来说,用户往往希望返回的文档中大部分或者全部查询词项之间的距离比较近,因为这表明返回文档中具有聚焦用户 查询意图的文本
考虑一个由两个或者多个查询词项构成的查询\[t_{1}, t_{2}, \ldots, t_{k}\],令文档中包含所有查询词项得最小窗口大小为\[\omega\],其取值为窗口内词的个数。如果文档中不包含所有的查询词项, 那么此时可以将ω设成一个非常大的数字。直观上讲,ω的值越小,文档d和查询匹配程度更高,即可以根据ω的大小来设计权重
查询分析及文档评分函数的设计
- 查询分析:将自由文本查询通过查询分析器,转化成带操作符的查询,比如对于rising interest rates的查询的分析如下:
- 查询rising interest rates这一短语
- 如果太少,转而分别查询 rising interest 和 interest rates 两个查询短语
- 如果太少,转而分别查询 rising ,interest 和 rates 这三个查询短语
- 评分函数的设计:必须融入向量空间计算、静态得分、邻近度加权或其他因素
搜索系统的组成

chap 7-Computing scores in a complete search system
https://xdren69.github.io/2020/09/16/information-retrieval-ch7/