chap 5-Index compression
压缩索引的目的:1.增加cache的利用率;2.加速数据从磁盘到内存的速度
本章介绍的压缩技术均为无损压缩,即压缩之后所有的原始信息都被保留;大小写转换、词干还原、和停用词剔除均是有损压缩技术
信息检索中词项的统计特性
- Heaps定律:对于词汇表大小的估计
- Zipf定律:对词项分布的建模
词典压缩
使用变长字符串
查询表中只存指针,每个词项均对应一个指针
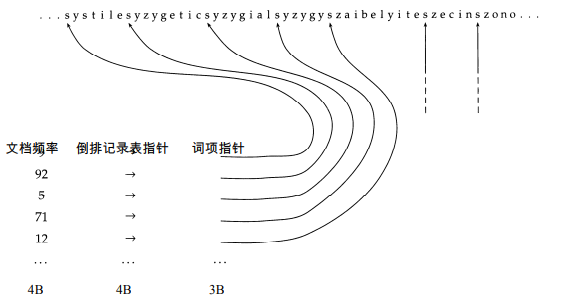
按块存储
块间二分查找,块内遍历(块内K个词项),减少指针数目

k越大,压缩率越高;但是查找效率越低

倒排记录表的压缩
倒排记录表中的内容为文档的序号
主要采用:1.可变字节码;2.Y编码这两种压缩方式
可变字节编码
利用整数个字节对同一单词的倒排记录表中的相邻文档间的间距进行编码,字节的后七位是间距的有效编码区,第一位是延续位(如果该位为1,表示结尾;否则不是)
举例如下:

Y编码
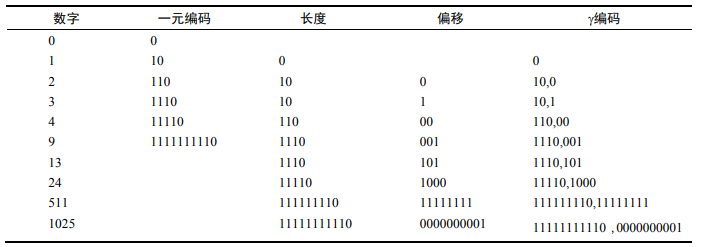
Y编码的组成:将间距G表示成长度和偏移两个部分进行变长编码,G的偏移实际上是G的二进制编码,但是前端的1被去掉;eg:对 13(二进制为 1101)进行编码,其偏移为 101。偏移的长度为3位,长度部分采用一元编码(一开始有连续个1,最后以0结尾,1的个数表示长度)。即为1110.
举例如下:
chap 5-Index compression
https://xdren69.github.io/2020/09/11/information-retrieval-ch5/