chap 3-Dictionaries and tolerant retrieval
本章主要讲解了如何对倒排索引进行优化,分为三个部分:对于词典部分的查询进行优化、对通配符查询的处理、拼写校正的问题以及基于发音的校正技术
词典搜索的数据结构
哈希表
容易产生冲突问题,尤其是词汇表不断变大的情况下
搜索树——二叉树、B树
- 二叉树:注意二叉树的平衡问题
- B树:适用于部分词典常驻磁盘的情况
通配符查询
使用B树和反向B树相结合
单一通配符:对于单词lemon,其中反向B树中的路径就是 root-n-o-m-e-l;对于查询se*mon,可以通过B-树来返回所有前缀为se且后缀非空的词项子集W,再通过反向B-树来返 回所有后缀为mon且前缀非空的词项子集R,然后,对W和R求交集W ∩ R
多通配符:通过穷举法检查返回的集合中的每个元素
轮排索引
此方法是对于正反向B树的改进,即只使用一棵B树
单一通配符:我们在字符集中引入一个新的符号$,用于标识词项结束;对于单词hello的轮排索引的结果如下所示:
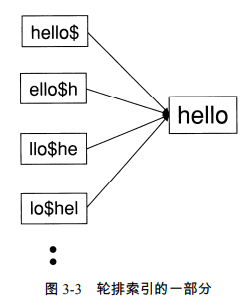
处理通配符时的应用:考虑通配符查询 m*n,这里的关键是将查询进行旋转让*号出现 在字符串末尾,即得到 n$m*,此时便可以用正向B树来解决
多通配符:通过穷举法检查返回的集合中的每个元素
K-gram索引
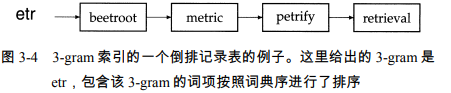
k-gram表示的是将每个单词按照k个字母来划分,分成字母片段对于 castle 来说,所有的 3-gram包括$ca、cas、ast、stl、tle 及 le$
本方法直接适用于多通配符,此时词汇表变为k-gram形式,而每个倒排记录表则由包含该k-gram的词项组成,而每个单词还会对应一个文章ID的倒排记录表
拼写校正
用于解决在用户输入拼写错误的查询词时,能检测到并还原为正确的查询词,最终返回正确查询词的查询结果。
拼写校正的实现
对于一个拼写错误的查询,在其可能的正确拼写中,选择“距离”最近或者邻近度最小的那个。在距离和邻居度相同的情况下,选择其他用户查询最频繁的
校正方法
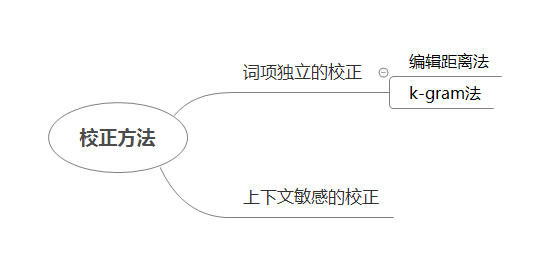
词项独立的校正方法
在对查询进行分词之后,只对单个查询词进行校正,此时很难检测到flew form Heathrow中的错误
- 编辑距离法
编辑距离的定义:将字符串s1转换为字符串s2所需要的最小编辑操作数(删除一个字符、替换一个字符、增加一个字符)
一般通过动态规划来计算,其算法描述为:
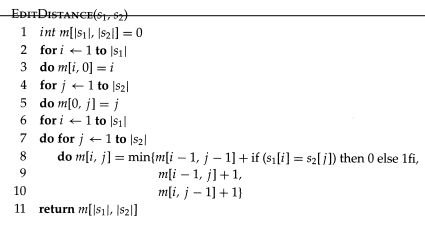
- K-gram法
原理:正确的目标查询词为待匹配词项包含查询 q(拼写错误) 中某个固定数目的 k-gram 即可
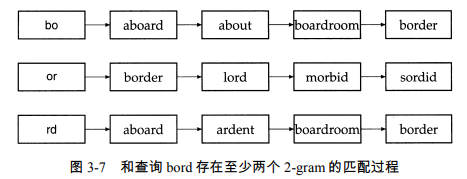
举例:假定我们想返回 bord 的 3 个 2-gram 中的至少 2 个词项,对倒排记录表的单遍扫描会返回满足该条件的所有词项,本例当中,这些词项包括 aboard、boardroom 及 border
- 混合法
首先使用 k-gram 索引返回可能是 q 的潜在正确拼写形式的词项集合,然后计算该集合中的每个元素和 q 之间的编辑距离并选择 具有较小距离的那些词项。
上下文敏感的拼写校正
尝试对短语中的每个词进行替换。比如对于上面 flew form Heathrow 的例子,我们 可能会返回如下短语 fled from Heathrow 和 flew fore Heathrow。对每个替换后的短语,搜索引擎 进行查找并确定最后的返回数目。
基于发音的校正技术
原理::(1)在名称转录时,元音是可以互换的;(2)发音相似的辅音字母归为一类。这就会导致相关的名称通常有相同的 soundex 编码结果
方法:使用soundex编码方法
chap 3-Dictionaries and tolerant retrieval
https://xdren69.github.io/2020/09/08/information-retrieval-ch3/