chap 2-The term vocabulary and postings lists
Document delineation and character sequence decoding
根据不同的编码方式,将字节序列转化为字符序列
文本的序列化处理
将文档和查询使用相同的方法转化为词条
关键术语的区分
- token: tokenization is the task of chopping it up into pieces, called tokens;
- type: A type is the class of all tokens term containing the same character sequence
- term: A term is a (perhaps normalized) type that is included in the IR system’s dictionary.
example: For example, if the document to be indexed is to sleep perchance to dream, then there are five tokens, but only four types (because there are two instances of to). However, if to is omitted from the index (as a stop word) , then there are only three terms: sleep, perchance, and dream.
需要解决的问题
分词问题:
英语:对于空格和连字符的处理
中文:无法通过空格来分词,词边界不明显
德语:对复合词进行拆分
去除停用词:通过文档集频率来选择停用词,频率越大说明越不具有特殊性(现代搜索系统的影响并不大)——一般先分词,后去除停用词
term normalization:将看起来不完全一致的多个词条归纳成一个等价类,如:anti-discriminatory和antidiscriminatory均映射成antidiscriminatory,一般的方法是构建同义词表,归一化的方法如下:
合并同义词表中多个词的查询结果
构建索引时,便对词进行扩展
词干还原(stemming)与词形归并(lemmatization)
- 词干还原:利用启发式规则去除两端前缀
- 词形归并:利用词汇表和词形分析
基于skip pointers的倒排记录表快速合并算法
只适用于AND操作,不适用于OR操作
算法图示:
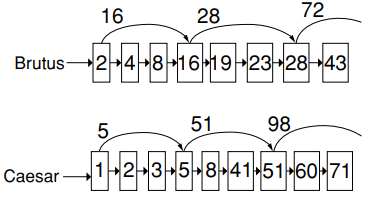
算法描述:

跳表指针的设置的位置:
每隔\[\sqrt{P}\]均设置一个跳表指针,指向下一个跳表指针的位置,P是跳表的长度
短语查询的解决方法
目前一般采用如下两种方式的混合
二元词索引
将文档中的每个连接词对看成一个短语
“stanford university palo alto”会被转化成“stanford university” and “university palo” and “palo alto”
扩展的二元词对:先进行词性标注,再将一个多词序列看成一个扩展的二元词
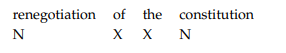
位置信息索引
在每个倒排记录中,存储该词在文本中出现的位置

举例如下:

chap 2-The term vocabulary and postings lists
https://xdren69.github.io/2020/09/07/information-retrieval-ch2/