整体认识——pytorch-learning(一)
重要提醒:本文不求原创和创新,是基于哈工大SCIR实验室的大佬们写的这篇文章的补充和拓展,因此会合原文有许多重复之处,请大家注意!
常用术语
- iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数,所需的数据量为1个batch的大小
- batch-size:1次迭代所使用的样本量
- epoch:1个epoch表示过了1遍训练集中的所有样本(包含多个batch的数据)
基本步骤
我们首先将模型的训练过程分为四个步骤,分别是:
- 输入处理模块 (X 输入数据,变成网络能够处理的Tensor类型)
- 模型构建模块 (主要负责从输入的数据,得到预测的y^, 这就是我们经常说的前向过程)
- 定义代价函数和优化器模块 (注意,前向过程只会得到模型预测的结果,只有当前模块负责自动求导和参数更新)
- 构建训练过程(迭代训练过程,就是下图表示的训练迭代过程)
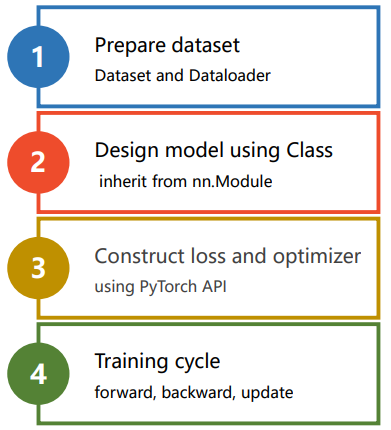
详细解释
一、数据处理
对于数据处理,最为简单的⽅式就是将数据组织成为⼀个 。但许多训练需要⽤到mini-batch,直接组织成Tensor不便于我们操作。pytorch为我们提供了Dataset和Dataloader两个类来方便的构建。
torch.utils.data.Dataset
继承Dataset 类需要override 以下⽅法:
1 | from torch utils. data import Dataset |
torch.utils.data.DataLoader
1 | torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False) |
DataLoader Batch。如果选择shuffle = True,每⼀个epoch 后,都会对所有数据打乱重新排序
mini-Batch batch_size 常⻅的使⽤⽅法如下:
1 | dataLoader = Dataloader(dataset, shuffle=True, batch size=32) |
shuffle=true表示每次取一个batch的数据前,先进行排序。官方注解如下:
shuffle (bool, optional) – set to
Trueto have the data reshuffled at every epoch (default:False).
二、模型构建
所有的模型都需要继承torch.nn.Module , 需要实现以下⽅法:
1 | class MyModel(torch, nn.Module): |
其中forward() ⽅法是前向传播的过程。在实现模型时,我们不需要考虑反向传播。
三、 定义代价函数和优化器
主要负责自动求导和参数更新,也就是反向传播部分
1 | criterion = torch.nn.BCELOSS(reduction='sum') # 代价函数 |
其中反向传播的基础:计算图,如下所示:
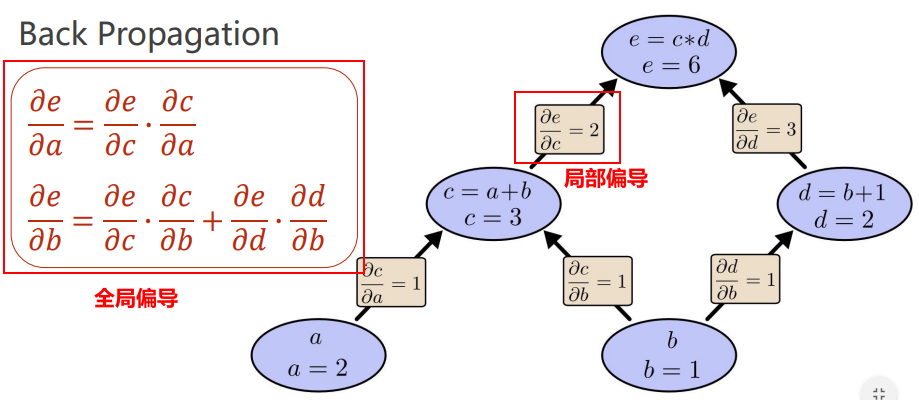
由图可以看出,全局偏导是由局部偏导根据链式法则,连续相乘而得出的
四、构建训练过程
1 | def train(epoch):#一个epoc的训练 |
引用
[1] 推荐给大家!Pytorch编写代码基本步骤思想_哈工大SCIR实验室的大佬们写的
[2] 河北工业大学刘洪普老师的视频教程
整体认识——pytorch-learning(一)