datawhale-零基础入门NLP-Task4
学习目标
不同于之前使用传统的机器学习方法,此次任务使用深度学习方法fastText来解决文本分类问题
文本表示方法(part 2)
之前的博客讨论了文本的表示方法:
- TF-IDF
- Bag of Words (AKA Count Vectors)
通过观察,我们可以发现它们存在一定的缺陷:每一段文本被表示所需的向量维度很大,两种方法均是vocab-size大小的;导致训练模型所需要的时间很长
于是我们思考用一种更加简短的方式来表达一段文本,于是想到了fastText模型,与之前的文本表示方法不同,其基本思想是将一个单词通过深度学习模型表示在一个更小维度的向量空间,然后将整个句子的词向量求和——由于使用了更小维度的向量空间,训练和预测都会变得更快!
fastText模型简介
fastText与word2vec、Glove均是对单词进行embedding的一种方法,本此任务我们先介绍fastText,其他两种之后会进行介绍
首先我们介绍embedding相比较与传统的文本表示方法(TF-IDF、Bag of Words)的优点:从task3我们可以知道,传统的文本表示方法形成的向量大小是vocab-size的,比较看重的是这段文本在每一个单词(或字)上的权重大小;而embedding会将一段文本中的每个单词映射到一个更小的空间中,使得每一个维度都有其意义(比如一个维度表示颜色,另一个维度表示大小之类的),因此展示在向量空间中,文本向量的距离可以用来衡量文本间的语义相似程度
接下来,我们介绍fastText这一模型
fastText的核心思想是:使用character级别的N-gram(之前我们使用过单词级别的n-gram,即将一段文本中连续的n个单词组成一个新的词语),而这里使用的是字符级的N-gram,即将一个单词中连续的n个字符拆出来,形成一个行的单词,具体的例子为:对于单词“where”,在n=3时,形成的单词为:<wh, whe, her, ere, re>以及where,因此从某种角度而言,字符级别的N-gram也是扩充词库的一种重要方法
fastText与word2vec(下一篇博客中会使用)相比,有如下优点:
在word2vec中,我们并没有直接利用构词学中的信息。无论是在Skip-Gram模型还是Continuous Bag of Words (CBOW)模型中,我们都将形态不同的单词用不同的向量来表示。例如,“dog”和“dogs”分别用两个不同的向量表示,而模型中并未直接表达这两个向量之间的关系。鉴于此,fastText提出了子词嵌入(subword embedding)的方法,从而试图将构词信息引入word2vec中的跳字模型 ....与Skip-Gram模型相比,fastText中词典规模更大,造成模型参数更多,同时一个词的向量需要对所有子词向量求和,继而导致计算复杂度更高。但与此同时,较生僻的复杂单词,甚至是词典中没有的单词,可能会从同它结构类似的其他词那里获取更好的词向量表示
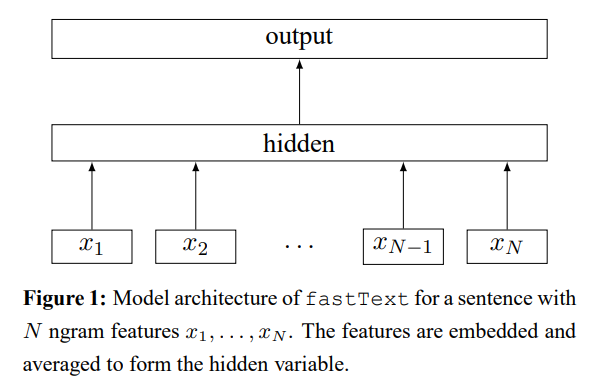
用fastText方法进行文本分类的模型架构如下所示:
代码实现
环境配置:
为了完成本次实验,需要首先安装安装包:我用的是conda下配置的python环境,直接使用会报错,说需要安装Microsoft Visual C++ 14.0的依赖;因此推荐离线安装,具体推荐参考这里
具体代码实现如下:
1 | import pandas as pd |
引用
[1]
datawhale-零基础入门NLP-Task4