datawhale-零基础入门NLP-Task2
学习目标
对需要训练的数据进行分析,同时通过可视化了解待训练数据的特点
前半部分的代码是官方文档提供的;作业部分属于自己完成的
数据分析
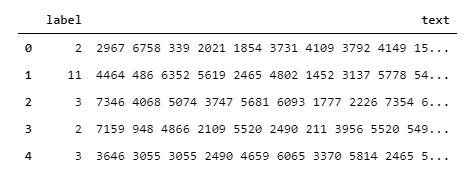
读入并观察数据的格式
1 | import pandas as pd |
分析每段文本的长度
1 | %pylab inline |
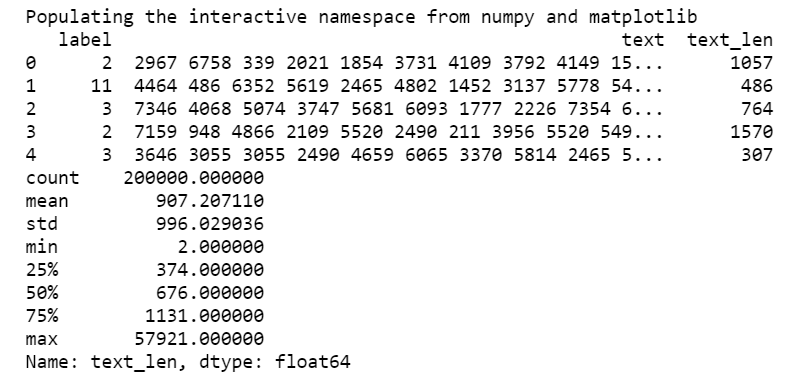
由此我们可以看到,对于所有文本,平均长度为907,最短为2,最长为57921
文本长度可视化分析
1 | _ = plt.hist(train_df['text_len'], bins=200) |
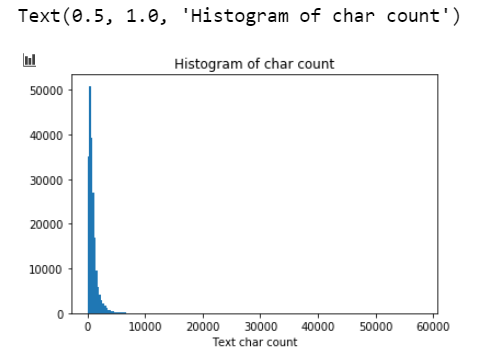
由此我们可以看出文本长度的分布是不均匀的
文本类别可视化分析
1 | train_df['label'].value_counts().plot(kind='bar') |
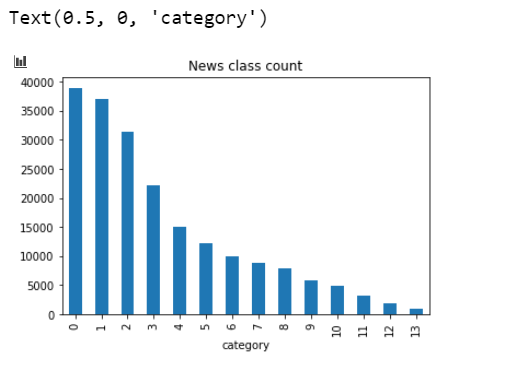
由此我们可以看出,不同类别的文本数也是不同的,可能对模型的训练精度产生影响
单词频次分析
先展示错误代码
1 | from collections import Counter |

错误原因:在执行到第三行时会因内存占用太多而导致程序奔溃;
解决办法:将训练数据分批读入,而不是一次性全部读入
再展示正确代码
1 | from collections import Counter |

表明一共出现了6869个汉字,其中3750号汉字出现的次数最多,为7482224次;3133号汉字出现的次数最少,为1次
统计覆盖率最高的前三个单词
1 | from collections import Counter |
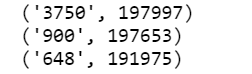
表明:编号'3750'的单词出现在了197997个句子中;编号'900'的单词出现在了197653个句子中;编号'648'的单词出现在了191975个句子中
本章作业
假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
1
2
3
4
5
6
7
8
9
10
11
12
13# 可以直接套用前一段代码,统计这三个标点在所有文本中出现的总次数即可
from collections import Counter
word_count = Counter()
chunk_iterator = pd.read_csv('../data/train_set.csv',sep='\t', chunksize=10000)
for chunk in chunk_iterator:
all_lines = ' '.join(list(chunk['text']))
word_count.update(all_lines.split(" "))
# 计算出总次数
sum = word_count['3750']+word_count['900']+word_count['648']
print(sum)
# 计算出平均次数
print(sum/200000.0)
统计每类新闻中出现次数对多的字符
1
2
3
4
5
6
7
8
9
10
11chunk_iterator = pd.read_csv('../data/train_set.csv',sep='\t', chunksize=10000)
for label in range(14):
word_count = Counter()
all_lines = ''
for chunk in chunk_iterator:
for index, l in enumerate(list(train_df['label'])):
if l==label:
all_lines = all_lines+' '+ train_df['text'][index]
word_count.update(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(label,word_count[0])
引用
datawhale-零基础入门NLP-Task2