datawhale-零基础入门NLP-Task1
题目理解
目标是用多种思路完成天池的NLP新手级题目零基础入门NLP - 新闻文本分类,题目的大意是训练一个模型,对不同的文本段进行分类,分成财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐这十四个类(记作0-13),其中会对输入的文本段做匿名化处理,如下所示:

流程划分
由于题目给出的训练用的文本段是匿名化的,无法进行分词操作,将整个比赛流程划分成特征提取和分类模型两个方面,因此在后续任务中会通过四种思路来完成这一题目,分别是:
TF-IDF + 机器学习分类器
TF-IDF用于对文本提取特征
FastText
FastText是入门款的词向量,由facebook提供
WordVec + 深度学习分类器
WordVec是进阶款的词向量
Bert词向量
Bert是高配款的词向量
测评指标
评价标准为类别f1_score的均值,结果越大越好。
对于评测标准的理解
评测标准的本质是用来筛选模型的好坏的,而模型的好坏在不同的条件下有不同的标准,因此评测标准也应该是多样的。
在本题中模型的作用是预测一段文本的类别,细化而言,即对于一段文本,判断其是否属于14类中的某一类(例如第3类),如果是模型预测是第3类就是positive,模型预测不是第3类就是negative,再结合实际情况,一共得到四类结果,如下图所示:
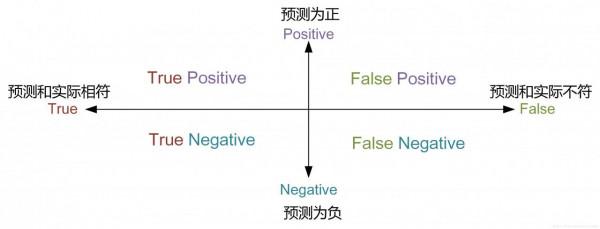
在实际中有很多种计算方式:
- Precision:
公式:\[Precision =\frac{ True Positive }{ True Positive + False Positive }\]
理解:这一标准关注的是对于某一类,在所有预测为positive的文本中,在实际中也是positive(即属于true positive)的概率
- 用途:Precision is a good measure to determine, when the costs of False Positive is high.(当分类器将一个实际negative的样本识别为positive会产生巨大损失时,即对false positive敏感,例如非垃圾邮件被识别成垃圾邮件)
- Recall:
公式:\[ Recall =\frac{True Positive}{True Positive+False Negative}\]
理解:这一标准关注的是对于某一类,在所有实际中为positive的文本中,在预测时也是positive(即属于true positive)的概率,也可以理解成模型对正样例的捕获能力
用途:Recall shall be the model metric we use to select our best model when there is a high cost associated with False Negative.(用于当一个正样例被分类错误会带来巨大损失的模型,即对false negative敏感,例如对强传染疾病的分类,将患病病人识别成不患病的)
- Accuracy:
- 公式:\[\mathrm{Accuracy}=\frac{\text { True Positive }+\text { True Negative }}{ \text { (True Positive }+\text { False Positive }+\text { True Negative }+\text { False Negative })}\]
- 理解:计算的是所有样本中分类正确(不论正样例还是负样例)占算有样本的比例
- 用途:It is most used when all the classes are equally important.(用于所有分类结果都一样重要时)
- F1_score:
- 公式:\[\mathrm{F} 1=\left(\frac{\text { Recall }^{-1}+\text {Precision }^{-1}}{2}\right)^{-1} =2 \times \frac{ Precision*Recall} {Precision+Recall}\]
- 理解:This is the harmonic mean of Precision and Recall and gives a better measure of the incorrectly classified cases than the Accuracy Metric(属于Precision和Recall的平衡点,即对Precision和Recall计算调和平均数)
对于F1_score和Accuracy的比较:
- Accuracy is used when the True Positives and True negatives are more important while F1-score is used when the False Negatives and False Positives are crucial
- Accuracy can be used when the class distribution is similar while F1-score is a better metric when there are imbalanced classes as in the above case.
- In most real-life classification problems, imbalanced class distribution exists and thus F1-score is a better metric to evaluate our model on.
参考
[1] Datawhale零基础入门NLP赛事 - Task1官方文档
[2] Accuracy, Precision, Recall or F1?
[3] 图片引用自这里
datawhale-零基础入门NLP-Task1